Nearly three years ago (July 2021) I wrote an article on this blog arguing that artificial intelligence is slowing down. Among other things I stated:
[C]an we keep growing our deep learning models to accommodate for more and more complex tasks? Can we keep increasing the number of parameters in these things to allow current AI to get better and better at what it does. Surely, we are going to hit a wall soon with our current technology?
Artificial Intelligence is Slowing Down, zbigatron.com
Then 7 months later I dared to write a sequel to that post in which I presented an article written for IEEE Spectrum. The article, entitled “Deep Learning’s Diminishing Returns – The cost of improvement is becoming unsustainable“, came to the same conclusions as I did (and more) regarding AI but it presented much harder facts to back its claims. The claims presented by the authors were based on an analysis of 1,058 research papers (plus additional benchmark sources).
A key finding of the authors’ research was the following: with the increase in performance of a DL model, the computational cost increases exponentially by a factor of nine (i.e. to improve performance by a factor of k, the computational cost scales by k^9). With this, we basically received an equation to estimate just how much money we’ll need to keep spending to improve AI.
Here we are, then, 3 years on. How have my opinion pieces fared after such a lengthy time (an eternity, in fact, considering how fast technology moves these days)? Since July 2021 we’ve seen releases of ChatGPT, Dall-E 2 and 3, Gemini, Co-Pilot, Midjourney, Sora… my goodness, the list is endless. Immense developments.
So, is AI slowing down? Was I right or wrong way back in 2021?
I think I was both right and wrong.
My initial claim was backed-up by Jerome Pesenti who at the time was head of AI at Facebook (the current head there now is none other than Yann LeCun). In an article for Wired Jerome stated the following:

When you scale deep learning, it tends to behave better and to be able to solve a broader task in a better way… But clearly the rate of progress is not sustainable… Right now, an experiment might [cost] seven figures, but it’s not going to go to nine or ten figures, it’s not possible, nobody can afford that…
In many ways we already have [hit a wall]. Not every area has reached the limit of scaling, but in most places, we’re getting to a point where we really need to think in terms of optimization, in terms of cost benefit
Article for Wired.com, Dec 2019 [emphasis mine]
I agreed with him back then. What I didn’t take into consideration (and neither did he) was that Big Tech would get on board with the AI mania. They are capable of dumping nine or ten figures at the drop of a hat. And they are also capable of fuelling the AI hype to maintain the large influx of money from other sources constantly entering the market. Below are recent figures regarding investments in the field of Artificial Intelligence:
- Anthropic, a direct rival of OpenAI, received at least $1.75 billion this year with a further $4.75 billion available in the near future,
- Inflection AI raised $1.3 billion for its very own chatbot called Pi,
- Abound raked in $600 million for its personal lending platform,
- SandboxAQ got $500 million for its idea to combine quantum sensors with AI,
- Mistral AI raised $113 million in June last year despite it being only 4 weeks old at the time and having no product at all to speak of. Crazy.
- and the list goes on…
Staggering amounts of money. But the big one is Microsoft who pumped US$10 billion into OpenAI in January this year. That goes on top of what they’ve already invested in the company.
US$10 billion is 11 figures. “[N]obody can afford that,” according to Jerome Pesenti (and me). Big Tech can, it seems!
Let’s look at some fresh research now on this topic.
Every year the influential AI Index is released, which is a comprehensive report that tracks, collates, distils, and visualises data and trends related to AI. It’s produced by a team of researchers and experts from academia and industry. This year the AI Index (released this month) has been “the most comprehensive to date” with a staggering 502 pages. There are some incredibly insightful graphs and information in the report but two graphs in particular stood out for me.
The first one shows the estimated training costs vs publication dates of leading AI models. Note that the y-axis (training cost) is in logarithmic scale.
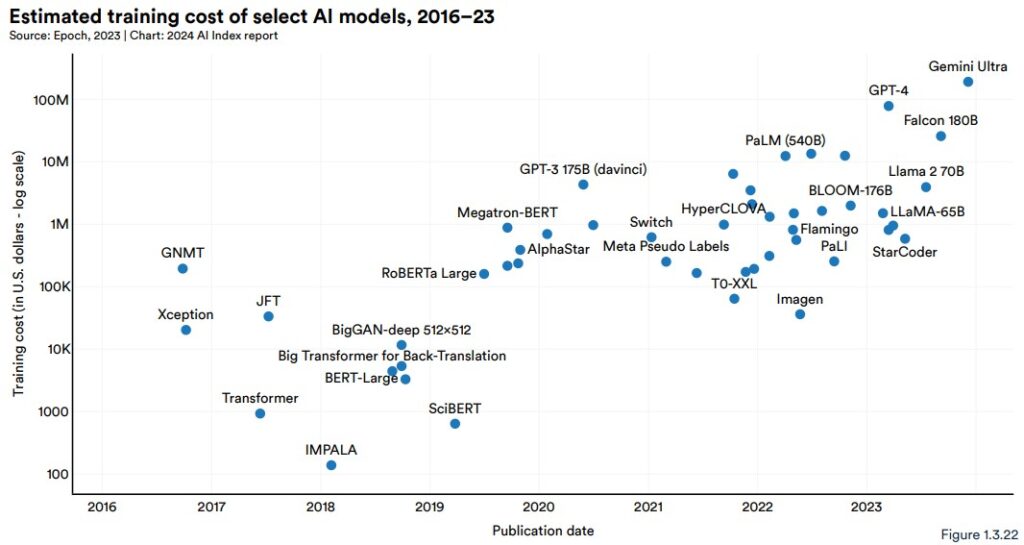
It’s clear that newer models are costing more and more. Way more (considering the log scale).
For actual training cost amounts, this graph provides a neat summary:

Note the GPT-4 (available to premium users of ChatGPT) and Gemini Ultra estimated training costs: US$78 million and US$191 million, respectively.
Gemini Ultra was developed by Google, GPT-4 was de-facto developed by Microsoft. Makes sense.
Where does this leave us? Considering the latest product releases, it seems like AI is not slowing down, yet. There still seems to be steam left in the industry. But with numbers like those presented above your average organisations just cannot compete any more. They’ve dropped out. It’s just the big boys left in the game.
Of course, the big boys have vast reserves of money so the race is on, for sure. We could keep going for a while like this. However, it’s surely fair to say once again that this kind of growth is unsustainable. Yes, more models will keep emerging that are going to get better and better. Yes, more and more money will be dropped into the kitty. But you can’t keep moving to the right of those graphs indefinitely. The equation still holds true that with the increase in performance of a DL model, the computational cost increases exponentially. Returns on investments will start to diminish (unless a significant breakthrough comes along that changes the way we do things – I discussed this topic in my previous two posts).
The craziness that big tech has brought to this whole saga is exciting and it has extended the life of AI quite significantly. However, the fact that only big players are left now who have wealth at their disposal larger than most countries in the world is a telling sign. AI is slowing down.
(I’ll see you in three years’ time again when I concede defeat and admit that I’ve been wrong. I truly hope I am because I want this to keep going. It’s been fun.)
To be informed when new content like this is posted, subscribe to the mailing list (or subscribe to my YouTube channel!):
(Note: If this post is found on a site other than zbigatron.com, a bot has stolen it – it’s been happening a lot lately)