Summary of review: This book is the best analysis of the state of Artificial Intelligence currently in print. It is a cool and level-headed presentation and discussion on a broad range of topics. An easy 5-stars.
“AI Superpowers: China, Silicon Valley, and the New World Order” is a book about the current state of Artificial Intelligence. Although published in late 2018 – light years ago for computer science – it is still very much relevant. This is important because it is the best book on AI that I have read to date. I’d hate for it to become obsolete because it is simply the most level-headed and accurate analysis of the topic currently in print.
 Professor Kai-Fu Lee knows what he’s talking about. He’s been at the forefront of research in AI for decades. From Assistant Professor at Carnegie Mellon University (where I currently teach at the Australian campus), to Principal Speech Scientist at Apple, to the founding director of Microsoft Research Asia, and then to the President of Google China – you really cannot top Kai-Fu’s resume in the field of AI. He is definitely a top authority, so we cannot but take heed of his words.
Professor Kai-Fu Lee knows what he’s talking about. He’s been at the forefront of research in AI for decades. From Assistant Professor at Carnegie Mellon University (where I currently teach at the Australian campus), to Principal Speech Scientist at Apple, to the founding director of Microsoft Research Asia, and then to the President of Google China – you really cannot top Kai-Fu’s resume in the field of AI. He is definitely a top authority, so we cannot but take heed of his words.
However, what made me take notice of his analyses was that he was speaking from the perspective of an “outsider”. I’ll explain what I mean.
So often, when it comes to AI, we see people being consumed by hype and/or by greed. The field of AI has moved at a lightning pace in the past decade. The media has stirred up a frenzy, imaginations are running wild, investors are pumping billions into projects, and as a result an atmosphere of excitement has descended upon researchers and the industry that makes impartial judgement and analysis extremely difficult. Moreover, greedy and charismatic people like Elon Musk are blatantly lying about the capabilities of AI and hence adding fuel to the fire of elation.
It wasn’t until Kai-Fu Lee was diagnosed with Stage IV lymphoma and given only a few months to live that he was also a full-fledged player and participant in this craze. Subsequently, he reassessed his life, his career, and decided to step away from his maniacal work schedule (to use his own words, pretty much). Time spent in a Buddhist monastery gave him further perspective on life and a clarity and composure of thought that shines through his book. He writes, then, in some respects as an “outsider” – but with forceful authority.
This is what I love about his work. Too often I cringe at people talking about AI soon taking over the world, AI being smarter than humans, etc. – opinions based on fantasy. Kai-Fu Lee straight out says that as things stand, we are nowhere near that level of intelligence exhibited by machines. Not by 2025 (as Elon Musk has said in the past), not even by 2040 (as a lot of others are touting) will we achieve this level. His discussion of why this is the case is based on pure and cold facts. Nothing else. (In fact, his reasonings are based on what I’ve said before on my blog, e.g. in this post: “Artificial Intelligence is Slowing Down“).
All analyses in this book are level-headed in this way, and it’s hard to argue with them as a result.
Some points of discussion in “AI Superpowers” that I, also a veteran of the field of AI, particularly found interesting are as follows:
- Data, the fuel of Deep Learning (as I discuss in this post), is going to be a principal factor in determining who will be the world leader in AI. The more data one has, the more powerful AI can be. In this respect, China with its lax laws on data privacy, larger population, coupled with cut-throat tactics in the procuring of AI research, and heavy government assistance and encouragement has a good chance to surpass the USA as a superpower of AI. For example, China makes 10 times more food deliveries and 4 times more ride-sharing calls than the US. That equates to a lot more data that can be processed by companies to fuel algorithms that improve their services.
- Despite AI not currently being capable of achieving human-level intelligence, Kai-Fu predicts, along with other organisations such as Gartner, that around 30-40% of professions will be significantly affected by AI. This means that huge upheavals and even revolutions in the workforce are due to take place. This, however, is my one major disagreement with Lee’s opinions. Personally, I believe the influence of AI will be a lot more gradual than Prof. Lee surmises and hence the time given to adjust to the upcoming changes will be enough to avoid potentially ruinous effects.
- No US company in China has made significant in-roads into Chinese society. Uber, Google, eBay, Amazon – all these internet juggernauts have utterly failed in China. The very insightful analysis of this phenomenon could only have been conducted so thoroughly by somebody who has lived and worked in China at the highest level.
- There is a large section in the book discussing the difference between humans and machines. This was another highlight for me. So many times, in the age of online learning (as I discuss in this post), remote working, social media, and especially automation, we neglect to factor in the importance of human contact and human presence. Once again, a level-headed analysis is presented that ultimately concludes that machines (chat-bots, robots, etc.) simply cannot entirely replace humans and human presence. There is something fundamentally different between us, no matter how far technology may progress. I’ve mentioned this adage of mine before: “Machines operate on the level of knowledge. We operate on the level of knowledge and understanding.” It’s nice to see an AI guru replicating this thought.
Conclusion
To conclude, then, “AI Superpowers: China, Silicon Valley, and the New World Order” is a fantastic dive into the current state of affairs surrounding AI in the world. Since China and the US are world leaders in this field, a lot of time is devoted to these countries: mostly on where they currently stand and where they’re headed. Kai-Fu Lee is a world authority on everything he writes about. And since he also does not have a vested interested in promoting his opinions, his words carry a lot more weight than others. As I’ve said above, this to me is the best book currently in print on this topic of AI. The fact that Prof. Lee also writes clearly and accessibly, even those unacquainted with technical terminology will be able to follow all that is presented in this work.
Rating: An easy 5 stars.
To be informed when new content like this is posted, subscribe to the mailing list:




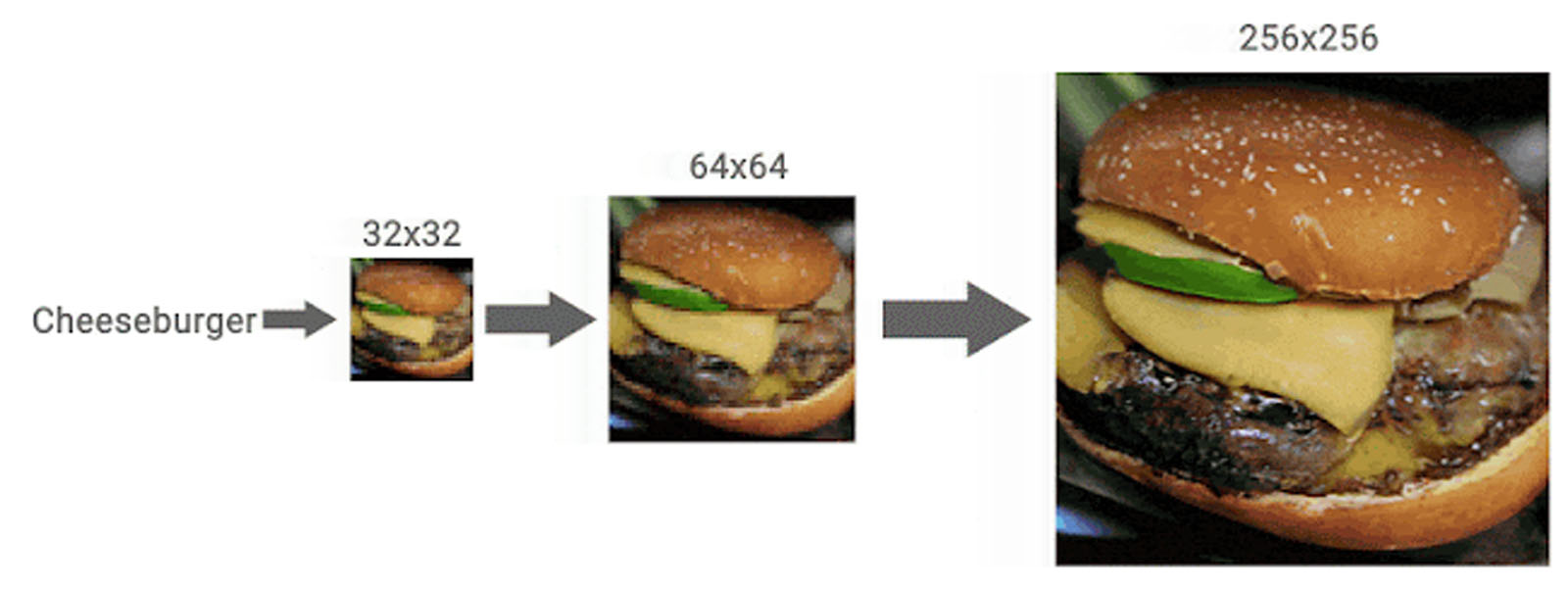






 When you scale deep learning, it tends to
When you scale deep learning, it tends to