Article content:
Last week I gave a few conference talks in which I talked about the exponential growth of AI over the past few years. One of the topics I covered was Natural Language Processing/Understanding (NLP/NLU) – the branch of AI that helps machines understand, manipulate, and use human language. We have come a seriously long way since Google Translate made its debut in 2006 (yes, it’s been that long!) or since chatbots first came to the fore. Machines can do incredible things now. And a lot of the progress can be attributed to the research done by OpenAI.
OpenAI was founded in 2015 by none other than Elon Musk and friends (e.g. Sam Ultman). It was initially a not-for-profit organisation whose mission was to safely improve AI for the betterment of human society. Since then a lot has changed: Elon Musk left the board in February 2018, the organisation changed its official status to for profit in 2019, and has since attracted a lot of attention from the corporate world, especially from that of Microsoft.
Over the years OpenAI has truly delivered incredible advancements in AI. Some of their products can only be labelled as truly exceptional: OpenAI Gym (its platform for reinforcement learning) and OpenAI Five (AI for the video game Dota 2) deserve honourable mentions here. But the real headlines have been made by their Generative Pre-Trained Transformer (GPT) language models.
GPT-1
GPT-1 was released by OpenAI in 2018. It was trained on the BooksCorpus dataset (7,000 unpublished books) and what made this model stand out from others was that it was trained as a “task-agnostic” model meaning that it was designed for, let’s say, “general purpose” use (rather than just sentiment analysis, for example). Moreover, it had a significant unsupervised pre-training phase, which allowed the model to learn from unannotated (raw) data. As the published academic paper states, this was a significant achievement because the abundant unlabeled text corpora available on the internet could now potentially be tapped:
By pre-training on a diverse corpus with long stretches of contiguous text our model acquires significant world knowledge and ability to process long-range dependencies which are then successfully transferred to solving discriminative tasks such as question answering, semantic similarity assessment, entailment determination, and text classification. [emphasis mine]
GPT-1 made headlines. It was something new and powerful and showed great potential because it demonstrated that language models could be generalised with relatively minimal human interference.
GPT-2
The following year in 2019 came GPT-2. And this bad boy made headlines worldwide (e.g. this BBC article). It was huge. And scary. Scary because of how good it was. So good that OpenAI decided to release the model in stages to allow people to get used to its capabilities. They said that GPT-2 could easily be used for nefarious purposes (e.g. to write fake news at large scale) and it was important that people and researchers were given a head-start to investigate properly this new “weapon” in NLP/NLU.
The power of GPT-2 came not necessarily from any new algorithm/process, per se, but from simply using a larger dataset and more parameters in the model. Basically, GPT-1 was improved by throwing more data at it: whereas GPT-1 was trained on 7,000 books, GPT-2 was trained on 8,000,000 websites (scraped from the Reddit website and outbound links – the dataset can be found here). To allow for the discovery of patterns in the Eglish language in such a massive dataset, the number of parameters used had to be increased: from 117 million (GPT-1) to 1.5 billion (GPT-2). A staggering increase. But like I said, this is where the power of GPT-2 came from – and it just shows that data, data, and once again, data is the key to AI at this present moment. If you can process this data, why not use it?
Let’s have a look at how good GPT-2 proved to be. This website allows you to get the model to generate text for you. You can type anything you want as a prompt and GPT-2 will continue the story, poem or article for you. I just typed the following into the prompt:
I am writing a blog post on computer vision.
GPT-2 came up with the following:
I am writing a blog post on computer vision. So please, if you are on facebook, do not leave comments there. I want to read your comments on my blog post. Thank you.
And then, as if magically, it went ahead and began to write my blog post:
So since I’m so busy with my part – time job, I have been making fun things for my students. Last week we played a game and the object was to cut more than everyone else. The most frugal way I had was to cut with a paper cutter. I was going to use scissors, but that would have been very expensive.
That is absolutely phenomenal. No wonder OpenAI got scared of GPT-2’s possibilities. How about writing books? Priya Dwivedi here famously trained GPT-2 on all the Harry Potter books just to see if it could get the model to write something in the Hogwart’s universe. It didn’t dissapoint:

That is pristine English. And also shows an amazing ability to learn and memorise contexts. E.g. that Hagrid is a big person, that Lockhart writes books, and that new books can appear in the library. Relations like this are being found in the original books and then used when generating text. Truly fantastic.
GPT-3
But then came GPT-3 in mid-2020. It caught a lot of people by surprise because we were still only just getting used to playing around with the power of GPT-2. And if GPT-2 was large, GPT-3 was monstrous in size. The largest thing the AI world had seen to date. It had 100 times more parameters (175 billion) than GPT-2 meaning that, crucially, even more data could be thrown at it in order for the model to learn significantly more language patterns and relations that we have in our beautiful language.
Let’s have a look at some of the things GPT-3 is capable of. Here is Qasim Munye asking the model a very detailed question in medicine:

GPT-3’s response was this:

As Qasim explains, this was not an easy task at all. One that even human doctors would have trouble with:

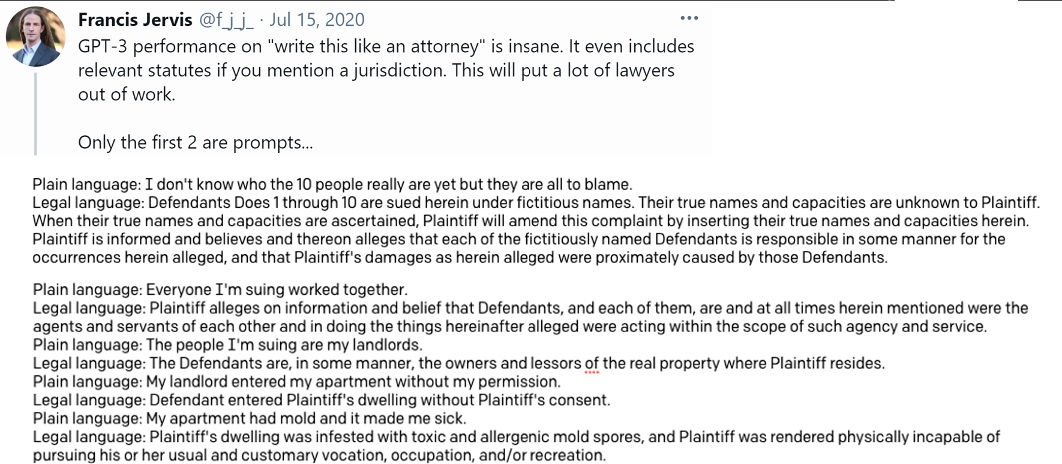
That’s pretty good. But it gets better. Here is Francis Jervis asking GPT-3 to translate “normal” English to legal English. This is incredible. Just look at how precise the result is:
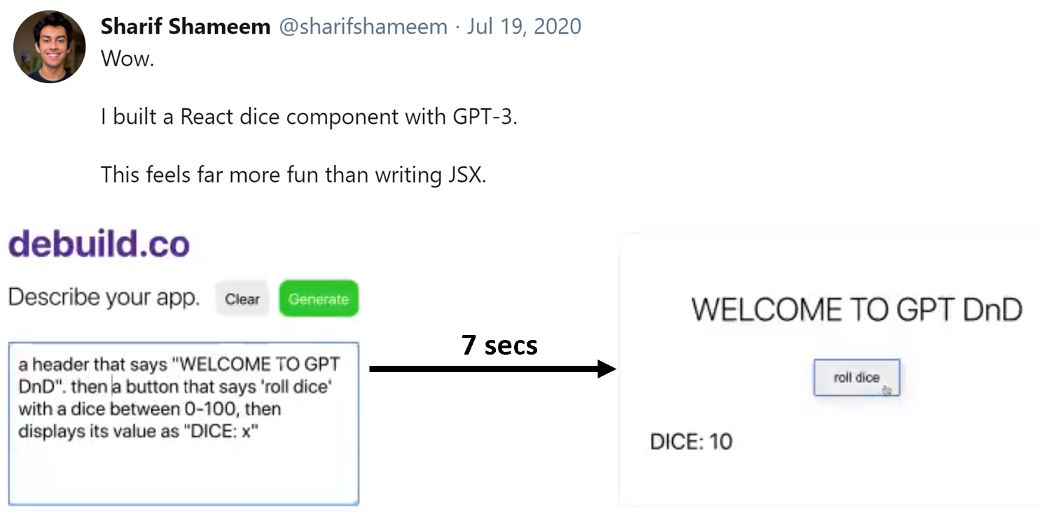
Lastly, what I want to show you is that GPT-3 is so good that it can even be used to program in computer languages. In fact, GPT-3 can code in CSS, JSX, and Python among others.
Since it’s release, numerous start-ups have popped up, as well as countless projects, to try to tap into GPT-3’s power. But to me, what came at the beginning of this year, blew my mind completely. And this is more in-line with computer vision (and the general scope of this blog).
DALL·E
DALL·E, released by OpenAI in January 5, 2021, is a 12-billion parameter version of GPT-3 trained to generate images from text descriptions. That is, OpenAI modified GPT-3 to generate images rather than text! You provide GPT-3 with a text caption and it will produce for you a set of images to match the text – without any human interaction. A completely astounding concept. But it works!
Let’s take a look at how well it does this:

What you see is the text input at the top given to DALL·E and its generated output.
Let me rehash again: you provide a machine text and it generates images for you that match the text. When I first saw this I got up, walked out of my office, and paced around the campus for a bit because I was in awe at what I had just seen.
Some more examples:


Incredible isn’t it? Especially the last example where two types of images are generated simultaneously, as requested by the user.
The sky’s the limit with technology such as this. It truly is. I can’t wait to see what the future holds in NLP/NLU and computer vision.
In my next post I will look at why I think, however, that AI is beginning to slow down. The exponential growth in innovation that I mentioned at the beginning of this post, I suspect, is coming to an end. But more on this next time. For now, enjoy the awe that I’m sure I’ve awoken in you.
To be informed when new content like this is posted, subscribe to the mailing list (or subscribe to my YouTube channel!):


3 Replies to “The Incredible Power of GPT-3 by OpenAI”