Deep learning (DL) revolutionised computer vision (CV) and artificial intelligence in general. It was a huge breakthrough (circa 2012) that allowed AI to blast into the headlines and into our lives like never before. ChatGPT, DALL-E 2, autonomous cars, etc. – deep learning is the engine driving these stories. DL is so good, that it has reached a point where every solution to a problem involving AI is now most probably being solved using it. Just take a look at any academic conference/workshop and scan through the presented publications. All of them, no matter who, what, where or when, present their solutions with DL.
Now, DL is great, don’t get me wrong. I’m lapping up all the achievements we’ve been witnessing. What a time to be alive! Moreover, deep learning is responsible for placing CV on the map in the industry, as I’ve discussed in previous posts of mine. CV is now a profitable and useful enterprise, so I really have nothing to complain about. (CV used to just be a predominantly theoretical field found usually only in academia due to the inherent difficulty of processing videos and images.)
Nonetheless, I do have one little qualm with what is happening around us. With the ubiquity of DL, I feel as though creativity in AI has been killed.
To explain what I mean, I’ll discuss first how DL changed the way we do things. I’ll stick to examples in computer vision to make things easier, but you can easily transpose my opinions/examples to other fields of AI.
Traditional Computer Vision
Before the emergence of DL if you had a task such as object classification/detection in images (where you try to write an algorithm to detect what objects are in an image), you would sit down and work out what features define each and every particular object that you wished to detect. What are the salient features that define a chair, a bike, a car, etc.? Bikes have two wheels, a handlebar and pedals. Great! Let’s put that into our code: “Machine, look for clusters of pixels that match this definition of a bike wheel, pedal, etc. If you find enough of these features, we have a bicycle in our photo!”
So, I would take a photo of my bike leaning against my white wall and I then feed it to my algorithm. At each iteration of my experiments I would work away by manually fine tuning my “bike definition” in my code to get my algorithm to detect that particular bike in my photo: “Machine, actually this is a better definition of a pedal. Try this one out now.”
Once I would start to see things working, I’d take a few more pictures of my bike at different angles and repeat the process on these images until I would get my algorithm to work reasonably well on these too.
Then it would be time to ship the algorithm to clients.
Bad idea! It turns out that a simple task like this becomes impossible to do because a bike in a real-world picture has an infinite number of variations. They come in different shapes, sizes, colours and then on top of that you have to add the different variations that occur with lighting and weather changes and occlusions from other objects. Not to mention the infinite number of angles into which you can position a bike. All these permutations are too much to handle for us mere humans: “Machine, actually I simply can’t give you all the possible definitions in terms of clusters of pixels of a bike wheel because there are too many parameters for me to deal with manually. Sorry.”
Incidentally, there’s a famous xkcd cartoon that captures the problem nicely:

Creativity in Traditional Computer Vision
Now, I’ve simplified the above process greatly and abstracted over a lot of things. But the basic gist is there: the real world was hard for AI to work in and to create workable solutions you were forced to be creative. Creativity on the part of engineers and researchers revolved around getting to understand the problem exceptionally well and then turning towards an innovative and visionary mind to find a perfect solution.
Algorithms abounded to assist us. For example, one would commonly employ things like edge detection, corner detection, and colour segmentation to simplify images to assist us with locating our objects, for example. The image below shows you how an edge detector works to “break down” an image:

Colour segmentation works by changing all shades of dominant colours in an image into one shade only, like so:

The second image is much easier to deal with. If you had to write an algorithm for a robot to find the ball, you would now ask the algorithm to look for patches of pixels of only ONE particular shade of orange. You would no longer need to worry about changes in lighting and shading that would affect the colour of the ball (like in the left image) because everything would be uniform. That is, all pixels that you would deal with would be one single colour. And suddenly your definitions of objects that you were trying to locate were not as dense. The number of parameters needed dropped significantly.
Machine learning would also be employed. Algorithms like SVM, k-means clustering, random decision forests, Naive Bayes were there at our disposal. You would have to think about which of these would best suit your use-case and how best to optimise them.
And then there were also feature detectors – algorithms that attempted to detect salient features for you to help you in the process of creating your own definitions of objects. The SIFT and SURF algorithms deserve Oscars for what they did in this respect back in the day.
Probably, my favourite algorithm of all time is the Viola-Jones Face Detection algorithm. It is ingenious in its simplicity and for the first time allowed face detection (and not only) to be performed in real-time in 2001. It was a big breakthrough in those days. You could use this algorithm to detect where faces were in an image and then focus your analysis on that particular area for facial recognition tasks. Problem simplified!
Anyway, all the algorithms were there to assist us in our tasks. When things worked, it was like watching a symphony playing in harmony. This algorithm coupled with this algorithm using this machine learning technique that was then fed through this particular task, etc. It was beautiful. I would go as far as to say that at times it was art.
But even with the assistance of all these algorithms, so much was still done manually as I described above – and reality was still at the end of the day too much to handle. There were too many parameters to deal with. Machines and humans together struggled to get anything meaningful to work.
The Advent of Deep Learning
When DL was introduced (circa 2012) it introduced the concept of end-to-end learning where (in a nutshell) the machine is told to learn what to look for with respect to each specific class of object. It works out the most descriptive and salient features for each object all on its own. In other words, neural networks are told to discover the underlying patterns in classes of images. What is the definition of a bike? A car? A washing machine? The machine works this all out for you. Wired magazine puts it this way:
If you want to teach a [deep] neural network to recognize a cat, for instance, you don’t tell it to look for whiskers, ears, fur, and eyes. You simply show it thousands and thousands of photos of cats, and eventually it works things out. If it keeps misclassifying foxes as cats, you don’t rewrite the code. You just keep coaching it.
The image below portrays this difference between feature extraction (using traditional CV) and end-to-end learning:
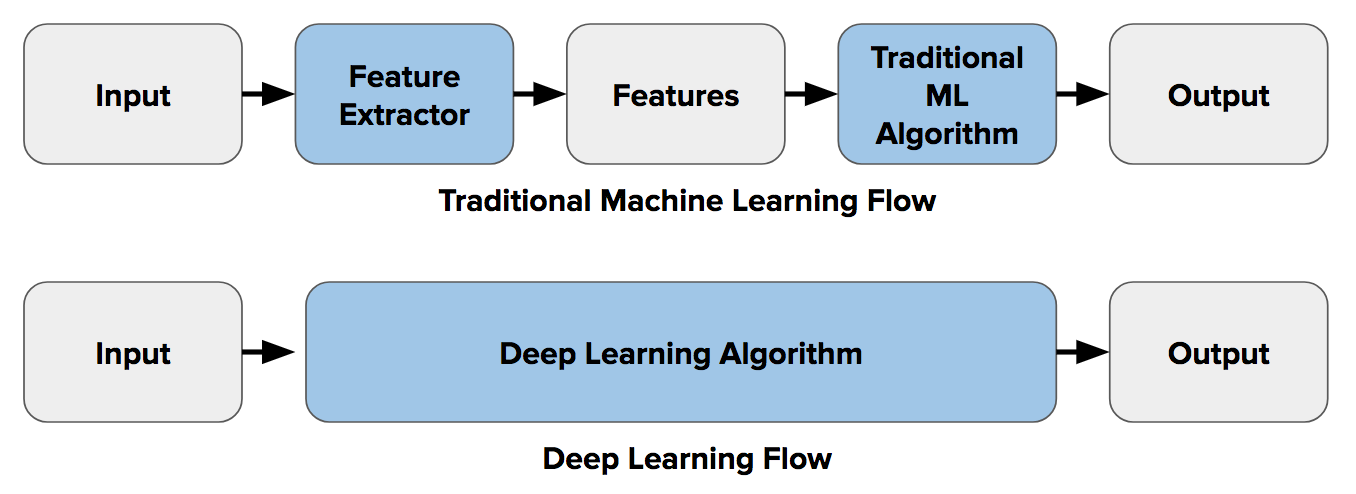
Deep learning works by setting up a neural network that can contain millions or even billions of parameters (neurons). These parameters are initially “blank”, let’s say. Then, thousands and thousands of images are sent through the network and slowly over time the parameters are aligned and adjusted accordingly.
Previously, we would have to adjust these parameters ourselves in one way or another, and not in a neural network – but we could only handle hundreds or thousands of parameters. We didn’t have the means to manage more.
So, deep learning has given us the possibility to deal with much, much more complex tasks. It has truly been a revolution for AI. The xkcd comic above is no longer relevant. That problem has been pretty much solved.
The Lack of Creativity in DL
Like I said, now when we have a problem to solve, we throw data at a neural network and then get the machine to work out how to solve the problem – and that’s pretty much it! The long and creative computer vision pipelines of algorithms and tasks are gone. We just use deep learning. There are really only two bottlenecks that we have to deal with: the need for data and time for training. If you have these (and money to pay for the electricity required to power your machines), you can do magic.
(In this article of mine I describe when traditional computer vision techniques still do a better job than deep learning – however, the art is dying out).
Sure, there are still many things that you have control over when opting for a deep neural network solution, e.g. number of layers, and of course hyper-parameters such as learning rate, batch size, and number of epochs. But once you get these more-or-less right, further tuning has diminishing returns.
You also have to choose the neural network that best suits your tasks: convolutional, generative, recurrent, and the like. We more or less know, however, which architecture works best for which task.
Let me put it to you this way: creativity has so much been eliminated from AI that there are now automatic tools available to solve your problems using deep learning. AutoML by Google is my favourite of these. A person with no background in AI or computer vision can use these tools with ease to get very impressive results. They just need to throw enough data at the thing and the tool works the rest out for them automatically.
I dunno, but that feels kind of boring to me.
Maybe I’m wrong. Maybe that’s just me. I’m still proud to be a computer vision expert but it seems that a lot of the fun has been sucked out of it.
However, the results that we get from deep learning are not boring at all! No way. Perhaps I should stop complaining, then.
To be informed when new content like this is posted, subscribe to the mailing list (or subscribe to my YouTube channel!):


