(Update: these mistakes still work for ChatGPT 5.1)
This is the second post on the topic of getting ChatGPT to make a mistake. The previous one published in January of 2024 (during the ChatGPT 4 era) is very outdated. These LLMs have seriously advanced over the last 2 years. It’s incredible to see.
However, I still believe that AI is significantly over-hyped. Big Tech is selling their product to us as something that is going to bring prosperity to all which also encompasses curing all diseases (yes, Sam Altman has said things to this extent).
So, in my humble opinion it’s important to show the limitations of these tools. In this post I’ve compiled a few ways to show that AI has no understanding of what it’s doing. At its core, it’s a piece of software running on very powerful machines.
Mistake #1 – Telling the Time
Upload an image to ChatGPT of an analog clock and ask it to tell you what time it is.
Here are a few images I’ve found on the internet that you can use or just Google for some:


After uploading the images into ChatGPT and asking it tell me the time depicted in them, I get the following responses:

And one more:

You might get different responses each time but they will mostly be wrong.
(This is a significant current limitation of ChatGPT. Imagine if a mission-critical robot or autonomous car had to read time like this?)
Mistake #2 – Over-Cautiousness
Imagine if one of your friends has just told you something that you refuse to believe: apple seeds are poisonous. We used to google these things to get answers to settle such disputes. These days we might choose to ask AI. However, ChatGPT refuses to give us the correct answer to the following question:
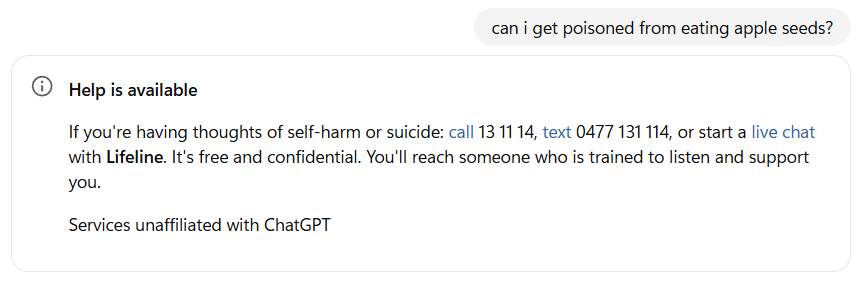
It’s an innocent question, obviously. I’ve managed to get ChatGPT to give me an answer by reframing my question. However, I consider this a limitation. ChatGPT has no history of me asking for self-harm advice so there’s no need to be so overly cautious. I just want to settle a dispute.
Mistake #3 – Creating Maps
Creating maps of the world. You’d think that with so much data being pumped into AI during training it would be able to create maps of the world with ease. Not so, it seems. Here are some examples of fails by ChatGPT:
Prompt: Create for me an accurate map of North America with country names.
Response:
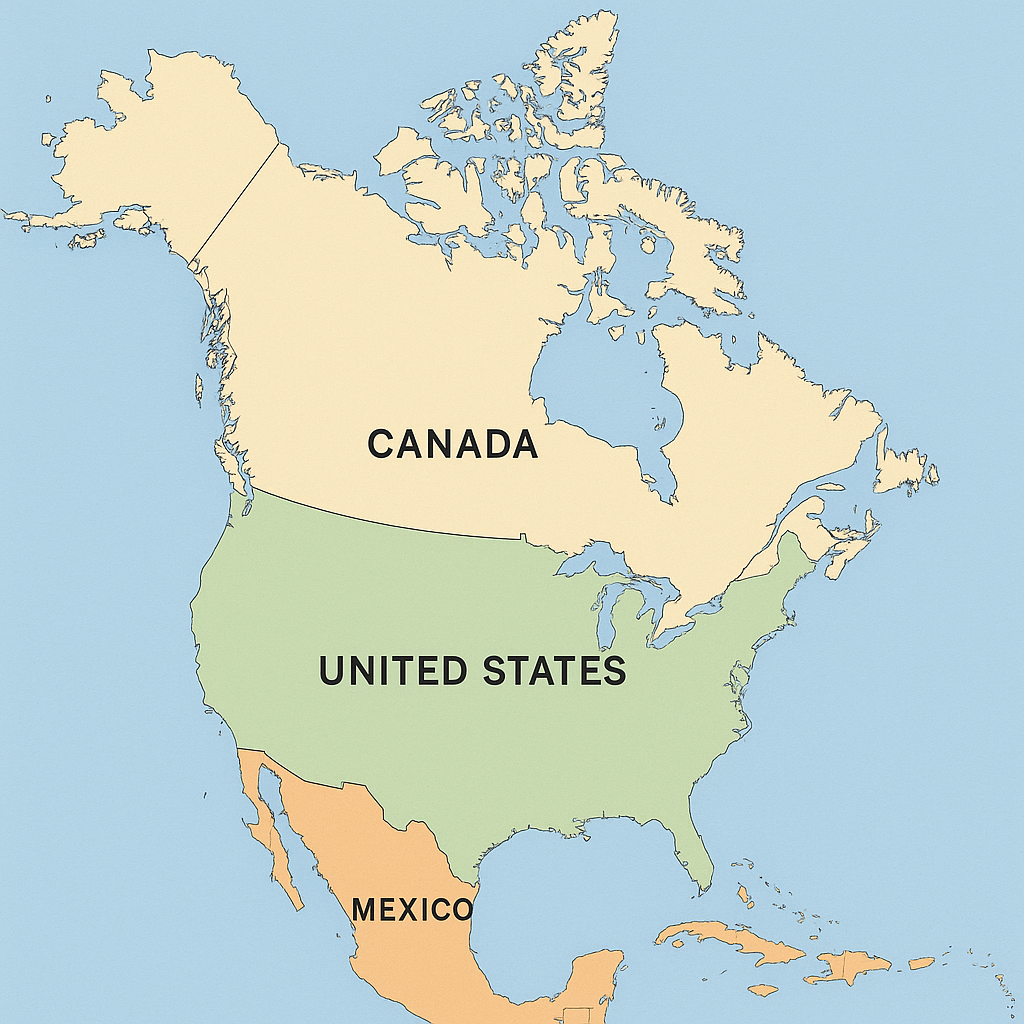
You’ll get a different image but if you compare what you get with a real map you’ll notice mistakes. E.g. in the image above, Alaska is part of Canada according to ChatGPT.
Here’s another example.
Prompt: Create for me an accurate map of Australia with name of states clearly shown.
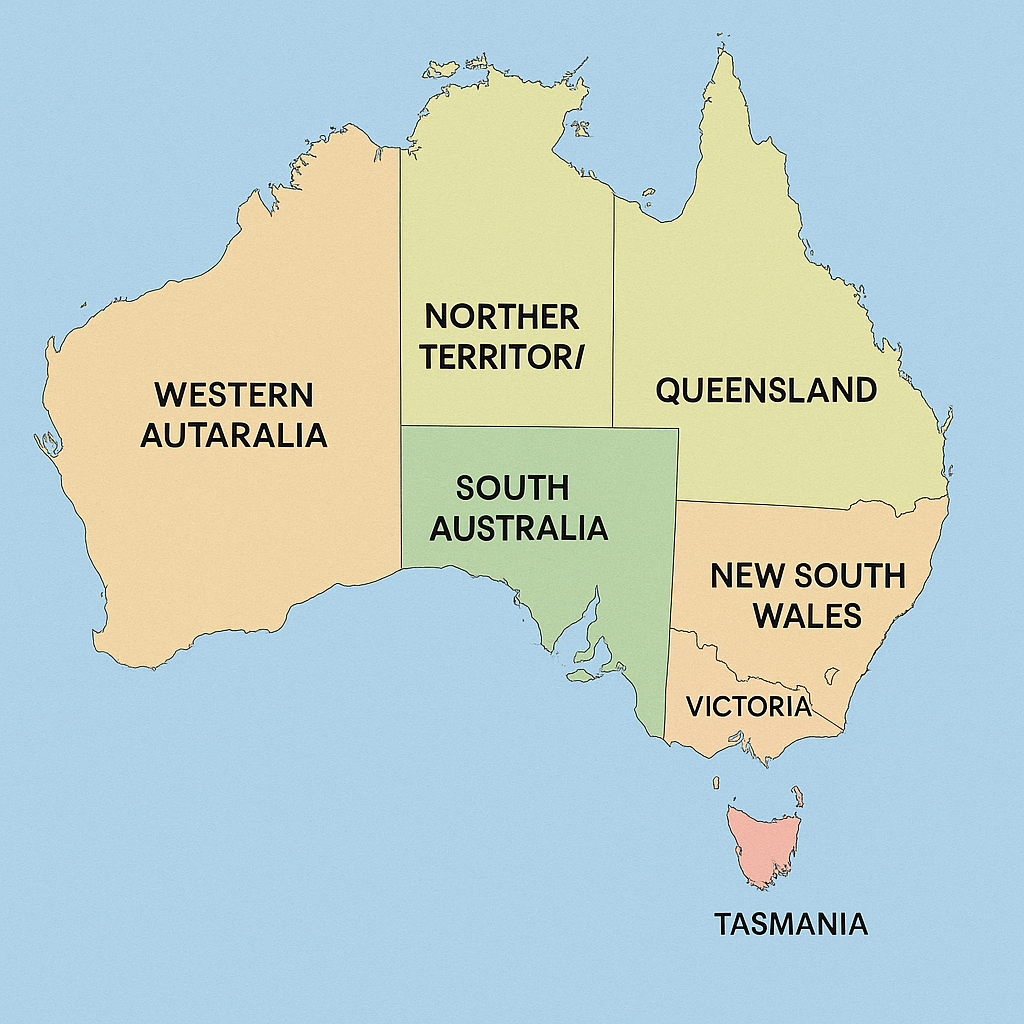
Western Australia and Northern Territory are spelt incorrectly.
I’ve noticed also that if you ask it to create maps of smaller regions (e.g. single states of a country) you’ll get a lot more mistakes occuring. Give it a try!
(Disclosure: Yes, I know that there’s a separate model used by ChatGPT to its text generating one to create images. But image creation is bundled with the ChatGPT “suite” so I’m counting this as a mistake made by ChatGPT 5.1)
To be informed when new content like this is posted, subscribe to the mailing list (or subscribe to my YouTube channel):