
As I’ve discussed in previous posts of mine, computer vision is growing faster than ever. In 2016, investments into US-based computer vision companies more than tripled since 2014 – from $100 million to $300 million. And it looks like this upward trend is going to continue worldwide, especially if you consider all the major acquisitions that were made in 2017 in the field, the biggest one being Intel’s purchase in March of Mobileye (a company specialising in computer vision-based collision prevention systems for autonomous cars) for a whopping $15 billion.
But today I want to take a look back rather than forward. I want to devote some time to present the early historical milestones that have led us to where we are now in computer vision.
This post, therefore, will focus on seminal developments in computer vision between the 60s and early 80s.
Larry Roberts – The Father of Computer Vision
Let’s start first with Lawrence Roberts. Ever heard of him? He calls himself the founder of the Internet. The case for giving him this title is strong considering that he was instrumental in the design and development of the ARPANET, which was the technical foundation of what you are surfing on now.
What is not well known is that he is also dubbed the father of computer vision in our community. In 1963 he published “Machine Perception Of Three-Dimensional Solids”, which started it all for us. There he discusses extracting 3D information about solid objects from 2D photographs of line drawings. He mentions things such as camera transformations, perspective effects, and “the rules and assumptions of depth perception” – things that we discuss to this very day.
Just take a look at this diagram from his original publication (which can be found here – and a more readable form can be found here):
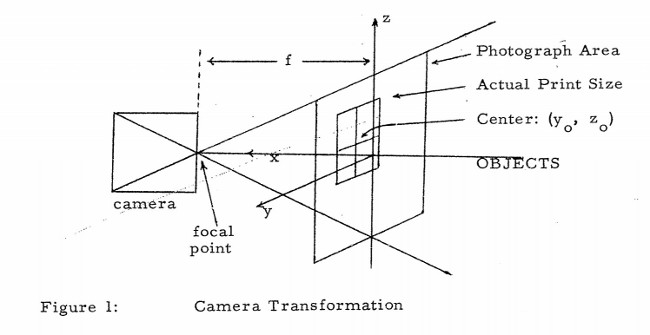
Open up any book on image processing and you will see a similar diagram in there discussing the relationship between a camera and an object’s projection on a 2D plane.
Funnily enough, Lawrence’s Wikipedia page does not give a single utterance to his work in computer vision, which is all the more surprising considering that the publication I mentioned above was his PhD thesis! Crazy, isn’t it? If I find the time, I’ll go over and edit that article to give him the additional credit that he deserves.
The Summer Vision Project
Lawrence Roberts’ thesis was about analysing line drawings rather than images taken of the real world. Work in line drawings was to continue for a long time, especially after the following important incident of 1966.
You’ve probably all heard the stories from the 50s and 60s of scientists predicting a bright future within a generation for artificial intelligence. AI became an academic discipline and millions was pumped into research with the intention of developing a machine as intelligent as a human being within 25 years. But it didn’t take long before people realised just how hard creating a “thinking” machine was going to be.
Well, computer vision has its own place in this ambitious time of AI as well. People then thought that constructing a machine to mimic the human visual system was going to be an easy task on the road to finally building a robot with human-like intelligent behaviour.
In 1966, Seymour Papert organised “The Summer Vision Project” at the MIT. He assigned this project to Gerald Sussman who was to co-ordinate a small group of students to work on background/foreground segmentation of real-world images with a final goal of extracting non-overlapping objects from them.
Only in the past decade or so have we been able to obtain good results in a task such as this. So, those poor students really did now know what they were in for. (Note: I write about why image processing is such a hard task in another post of mine). I couldn’t find any information on exactly how much they were able to achieve over that summer but this will definitely be something I will try to find out if I ever get to visit the MIT in the United States.
Luckily enough, we also have access to the original memo of this project available to us – which is quite neat. It’s definitely a piece of history for us computer vision scientists. Take a look at the abstract (summary) of the project from the memo from 1966 (the full version can be found here):

Continued Work with Line Drawings
In the 1970s work continued with line drawings because real-world images were just too hard to handle at the time. To this extent, people were regularly looking into extracting 3D information about blocks from 2D images.
Line labelling was an interesting concept being looked at in this respect. The idea was to try to discern a shape in a line drawing by first attempting to annotate all the lines it was composed of accordingly. Line labels would include convex, concave, and occluded (boundary) lines. An example of a result from a line labelling algorithm can be seen below:
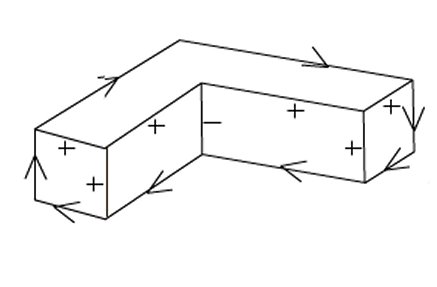
Two important people in the field of line labelling were David Huffman (“Impossible objects as nonsense sentences”. Machine Intelligence, 8:475-492, 1971) and Max Clowes (“On seeing things”. Artificial Intelligence, 2:79-116, 1971) who both published their line labelling algorithms independently in 1971.
In the genre of line labelling, interesting problems such as the one below were also looked at:
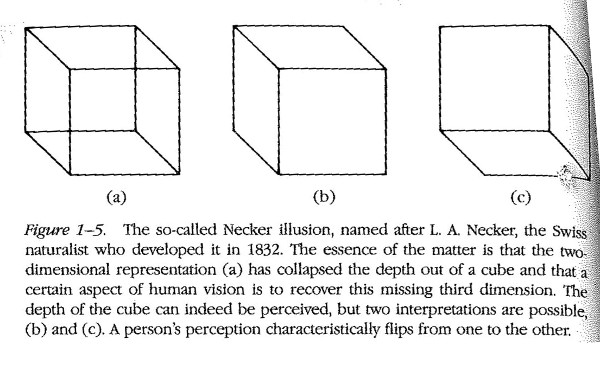
The image above was taken from a seminal book written by David Marr at the MIT entitled “Vision: A computational investigation into the human representation and processing of visual information”. It was finished around 1979 but posthumously published in 1982. In this book Marr proposes an important framework to image understanding that is used to this very day: the bottom-up approach. The bottom-up approach, as Marr suggests, uses low-level image processing algorithms as stepping-stones towards attaining high-level information.
(Now, for clarification, when we say “low-level” image processing, we mean tasks such as edge detection, corner detection, and motion detection (i.e. optical flow) that don’t directly give us any high-level information such as scene understanding and object detection/recognition.)
From that moment on, “low-level” image processing was given a prominent place in computer vision. It’s important to also note that Marr’s bottom-up framework is central to today’s deep learning systems (more on this in a future post).
Computer Vision Gathers Speed
So, with the bottom-up model approach to image understanding, important advances in low-level image processing began to be made. For example, the famous Lukas-Kanade optical flow algorithm, first published in 1981 (original paper available here), was developed. It is still so prominent today that it is a standard optical flow algorithm included in the OpenCV library. Likewise, the Canny edge detector, first published in 1986, is again widely used today and is also available in the OpenCV library.
The bottom line is, computer vision started to really gather speed in the late 80s. Mathematics and statistics began playing a more and more significant role and the increase in speed and memory capacity of machines helped things immensely also. Many more seminal algorithms followed this upward trend, including some famous face detection algorithms. But I won’t go into this here because I would like to talk about breakthrough CV algorithms in a future post.
Summary
In this post I looked at the early history of computer vision. I mentioned Lawrence Roberts’ PhD on things such as camera transformations, perspective effects, and “the rules and assumptions of depth perception”. He got the ball rolling for us all and is commonly regarded as the father of computer vision. The Summer Vision Project of 1966 was also an important event that taught us that computer vision, along with AI in general, is not an easy task at all. People, therefore, focused on line drawings until the 80s when Marr published his idea for a bottom-up framework for image understanding. Low-level image processing took off spurred on by advancements in the speed and memory capacity of machines and a stronger mathematical and statistical vigour. The late 80s and onwards saw tremendous developments in CV algorithm but I will talk more about this in a future post.
To be informed when new content like this is posted, subscribe to the mailing list (or subscribe to my YouTube channel!):



One Reply to “The Early History of Computer Vision”