This is another post that’s been inspired by a question that has been regularly popping up in forums:
Has deep learning superseded traditional computer vision?
Or in a similar vein:
Is there still a need to study traditional computer vision techniques when deep learning seems to be so effective?
These are good questions. Deep learning (DL) has certainly revolutionised computer vision (CV) and artificial intelligence in general. So many problems that once seemed improbable to be solved are solved to a point where machines are obtaining better results than humans. Image classification is probably the prime example of this. Indeed, deep learning is responsible for placing CV on the map in the industry, as I’ve discussed in previous posts of mine.
But deep learning is still only a tool of computer vision. And it certainly is not the panacea for all problems. So, in this post I would like to elaborate on this. That is, I would like to lay down my arguments for why traditional computer vision techniques are still very much useful and therefore should be learnt and taught.
I will break the post up into the following sections/arguments:
- Deep learning needs big data
- Deep learning is sometimes overkill
- Traditional CV will help you with deep learning
But before I jump into these arguments, I think it’s necessary to first explain in detail what I mean by “traditional computer vision”, what deep learning is, and also why it has been so revolutionary.
Background Knowledge
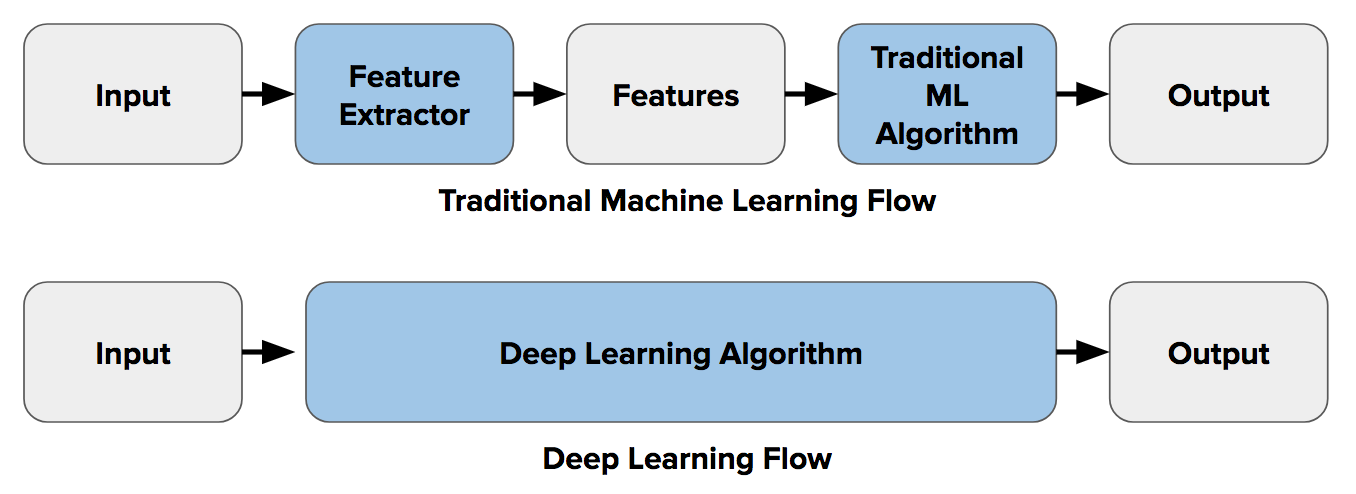
Before the emergence of deep learning if you had a task such as image classification, you would perform a step called feature extraction. Features are small “interesting”, descriptive or informative patches in images. You would look for these by employing a combination of what I am calling in this post traditional computer vision techniques, which include things like edge detection, corner detection, object detection, and the like.
In using these techniques – for example, with respect to feature extraction and image classification – the idea is to extract as many features from images of one class of object (e.g. chairs, horses, etc.) and treat these features as a sort of “definition” (known as a bag-of-words) of the object. You would then search for these “definitions” in other images. If a significant number of features from one bag-of-words are located in another image, the image is classified as containing that specific object (i.e. chair, horse, etc.).
The difficulty with this approach of feature extraction in image classification is that you have to choose which features to look for in each given image. This becomes cumbersome and pretty much impossible when the number of classes you are trying to classify for starts to grow past, say, 10 or 20. Do you look for corners? edges? texture information? Different classes of objects are better described with different types of features. If you choose to use many features, you have to deal with a plethora of parameters, all of which have to be fine-tuned by you.
Well, deep learning introduced the concept of end-to-end learning where (in a nutshell) the machine is told to learn what to look for with respect to each specific class of object. It works out the most descriptive and salient features for each object. In other words, neural networks are told to discover the underlying patterns in classes of images.
So, with end-to-end learning you no longer have to manually decide which traditional computer vision techniques to use to describe your features. The machine works this all out for you. Wired magazine puts it this way:
If you want to teach a [deep] neural network to recognize a cat, for instance, you don’t tell it to look for whiskers, ears, fur, and eyes. You simply show it thousands and thousands of photos of cats, and eventually it works things out. If it keeps misclassifying foxes as cats, you don’t rewrite the code. You just keep coaching it.
The image below portrays this difference between feature extraction (using traditional CV) and end-to-end learning:
So, that’s the background. Let’s jump into the arguments as to why traditional computer vision is still necessary and beneficial to learn.
Deep Learning Needs Big Data
First of all, deep learning needs data. Lots and lots of data. Those famous image classification models mentioned above are trained on huge datasets. The top three of these datasets used for training are:
- ImageNet – 1.5 million images with 1000 object categories/classes,
- Microsoft Common Objects in Context (COCO) – 2.5 million images, 91 object categories,
- PASCAL VOC Dataset – 500K images, 20 object categories.
Easier tasks than general image classification will not require this much data but you will still need a lot of it. What happens if you can’t get that much data? You’ll have to train on what you have (yes, some techniques exist to boost your training data but these are artificial methods).
But chances are a poorly trained model will perform badly outside of your training data because a machine doesn’t have insight into a problem – it can’t generalise for a task without seeing data.
And it’s too difficult for you to look inside the trained model and tweak things around manually because a deep learning model has millions of parameters inside of it – each of which is tuned during training. In a way, a deep learning model is a black box.
Traditional computer vision gives you full transparency and allows you to better gauge and judge whether your solution will work outside of a training environment. You have insight into a problem that you can transfer into your algorithm. And if anything fails, you can much more easily work out what needs to be tweaked and where.
Deep Learning is Sometimes Overkill
This is probably my favourite reason for supporting the study of traditional computer vision techniques.
Training a deep neural network takes a very long time. You need dedicated hardware (high-powered GPUs, for example) to train the latest state-of-the-art image classification models in under a day. Want to train it on your standard laptop? Go on a holiday for a week and chances are the training won’t even be done when you return.
Moreover, what happens if your trained model isn’t performing well? You have to go back and redo the whole thing again with different training parameters. And this process can be repeated sometimes hundreds of times.
But there are times when all this is totally unnecessary. Because sometimes traditional CV techniques can solve a problem much more efficiently and in fewer lines of code than DL. For example, I once worked on a project to detect if each tin passing through on a conveyor belt had a red spoon in it. Now, you can train a deep neural network to detect spoons and go through the time-consuming process outlined above, or you can write a simple colour thresholding algorithm on the colour red (any pixel within a certain range of red is coloured white, every other pixel is coloured black) and then count how many white pixels you have. Simple. You’re done in an hour!
Knowing traditional computer vision can potentially save you a lot of time and unnecessary headaches.
Traditional Computer Vision will Improve your Deep Learning Skills
Understanding traditional computer vision can actually help you be better at deep learning.
For example, the most common neural network used in computer vision is the Convolutional Neural Network. But what is a convolution? It’s in fact a widely used image processing technique (e.g. see Sobel edge detection). Knowing this can help you understand what your neural network is doing under the hood and hence design and fine-tune it better to the task you’re trying to solve.
Then there is also a thing called pre-processing. This is something frequently done on the data that you’re feeding into your model to prepare it for training. These pre-processing steps are predominantly performed with traditional computer vision techniques. For example, if you don’t have enough training data, you can do a task called data augmentation. Data augmentation can involve performing random rotations, shifts, shears, etc. on the images in your training set to create “new” images. By performing these computer vision operations you can greatly increase the amount of training data that you have.
Conclusion
In this post I explained why deep learning has not superseded traditional computer vision techniques and hence why the latter should still be studied and taught. Firstly, I looked at the problem of DL frequently requiring lots of data to perform well. Sometimes this is not a possibility and traditional computer vision can be considered as an alternative in these situations. Secondly, occasionally deep learning can be overkill for a specific task. In such tasks, standard computer vision can solve a problem much more efficiently and in fewer lines of code than DL. Thirdly, knowing traditional computer vision can actually make you better at deep learning. This is because you can better understand what is happening under the hood of DL and you can perform certain pre-processing steps that will improve DL results.
In a nutshell, deep learning is just a tool of computer vision that is certainly not a panacea. Don’t only use it because it’s trendy now. Traditional computer vision techniques are still very much useful and knowing them can save you time and many headaches.
To be informed when new content like this is posted, subscribe to the mailing list (or subscribe to my YouTube channel!):



Very nice article.
I have worked with machine learning (applied to signal processing, not computer vision) during my PhD and I wondered whether the very good results obtained with deep learning would render machine learning obsolete. This article was a fresh reminder that deep learning has its weak points where ML can shine.
Good job.
Appreciate your comment. Congrats on your PhD! Zig
Thanks for the post 🙂 I used to asociate CV with CNN, and I was wondering what methods (as the treshold on pixels with a certain color) can be used instead, and if there was a documentation somewhere of all these methods ?
Ty !
Hello Martin. Thanks for you comment but I don’t quite understand your question. Do you mean what other layers one can use in a CNN other than convolutional? Send me an email, and we can start talking there. Zig
Thank you for posting this Article, I’m currently reading about Image Captioning using Deep Learning , and I needed to know the main difference between Traditional CV techniques and deep CNN, this helped me a lot.
I’m glad I could be of help!
This post is really a pleasant one it assists neew net viewers, who are wishing
in favor of blogging.
Thank you for your kind comment!