
In my previous post I looked at the unprecedented growth of computer vision in the industry. 10 years ago computer vision was nowhere to be seen outside of academia. But things have since changed significantly. A telling sign of this is the consistent tripling each year of venture capital funding in computer vision. And Intel’s acquisition of Mobileye in March 2017 for a whopping US$15.3 billion just sums up the field’s achievements.
In that post, however, I only briefly touched upon the reasons behind this incredible growth. The purpose of this article, then, is to fill that gap.
In this respect, I will discuss the top 4 reasons behind the growth of computer vision in the industry. I’ll do so in the following order:
- Advancements in hardware
- The emergence of deep learning
- The advent of large datasets
- The increase in computer vision applications
Better and More Dedicated Hardware
I mentioned in another post of mine that one of the main reasons why image processing is such a difficult problem is that it deals with an immense amount of data. To process this data you need memory and processing power. These have been increasing in size and power regularly for over 50 years (cf. Moore’s Law).
Such increases have allowed for algorithms to run faster to the point where more and more things are now capable of being run in real-time (e.g. face recognition).
We have also seen an emergence and proliferation of dedicated pieces of hardware for graphics and image processing calculations. GPUs are the prime example of this. A GPU clock speed may generally be slower than a regular CPU’s, but it can still outperform one for these specific tasks.
Dedicated pieces of hardware are becoming so highly prized nowadays in computer vision that numerous companies have started designing and producing them. Just two weeks ago, for example, Ambarella announced two new chips designed for computer vision processing with chiefly autonomous cars, drones, and security cameras in mind. And last year, Mythic, a startup based in California, raised over US$10 million to commercialise their own deep learning focused pieces of hardware.
The Emergence of Deep Learning
Deep learning, a subfield of machine learning, has been revolutionary in computer vision. Because of it machines are now getting better results than humans in important tasks such as image classification (i.e. detecting what object is in an image).
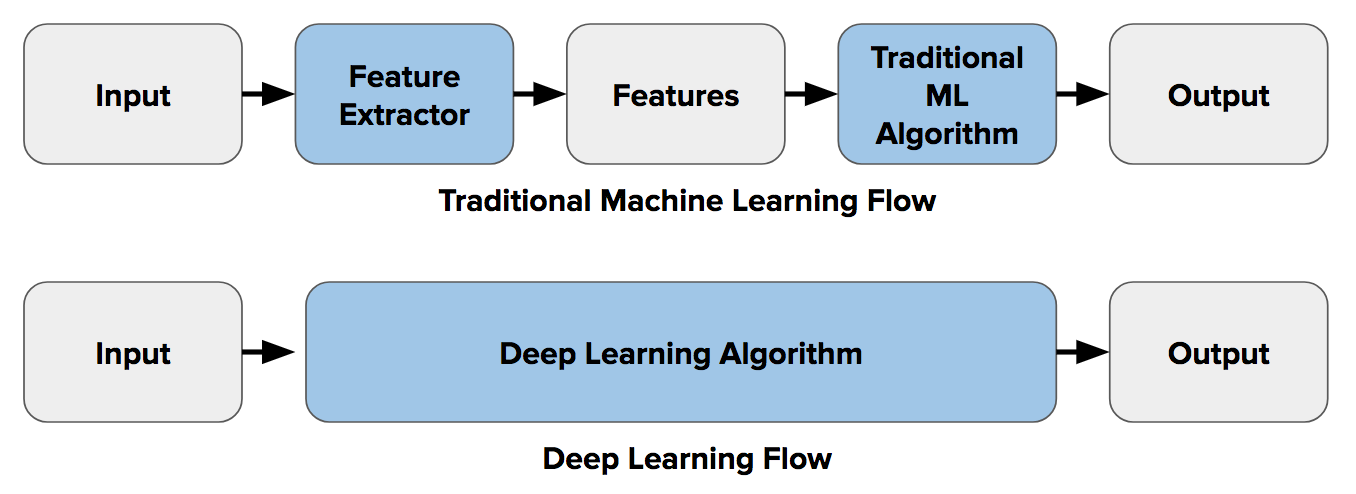
Previously, if you had a task such as image classification, you would perform a step called feature extraction. Features are small “interesting”, descriptive or informative patches in images. The idea is to extract as many of these from images of one class of object (e.g. chairs, horses, etc.) and treat these features as a sort of “definition” (known as a bag-of-words) of the object. You would then search for these “definitions” in other images. If a significant number of features from one bag-of-words are located in another image, the image is classified as containing that specific object (i.e. chair, horse, etc.).
The difficulty with this approach is that you have to choose which features to look for in each given image. This becomes cumbersome and pretty much impossible when the number of classes you are trying to classify for starts to grow past, say, 10 or 20. Do you look for corners? edges? texture information? Different classes of objects are better described with different types of features. If you choose to use many features, you have to deal with a plethora of parameters, all of which have to be fine-tuned.
Well, deep learning introduced the concept of end-to-end learning where (in a nutshell) the machine is told to learn what to look for with respect to each specific class of object. It works out the most descriptive and salient features for each object. In other words, neural networks are told to discover the underlying patterns in classes of images.
The image below portrays this difference between feature extraction and end-to-end learning:
Deep learning has proven to be extremely successful for computer vision. If you look below at the graph I used in my previous post showing capital investments into US-based computer vision companies since 2011, you can see that when deep learning became mainstream in around 2014/2015, investments suddenly doubled and have been growing at a regular rate since.
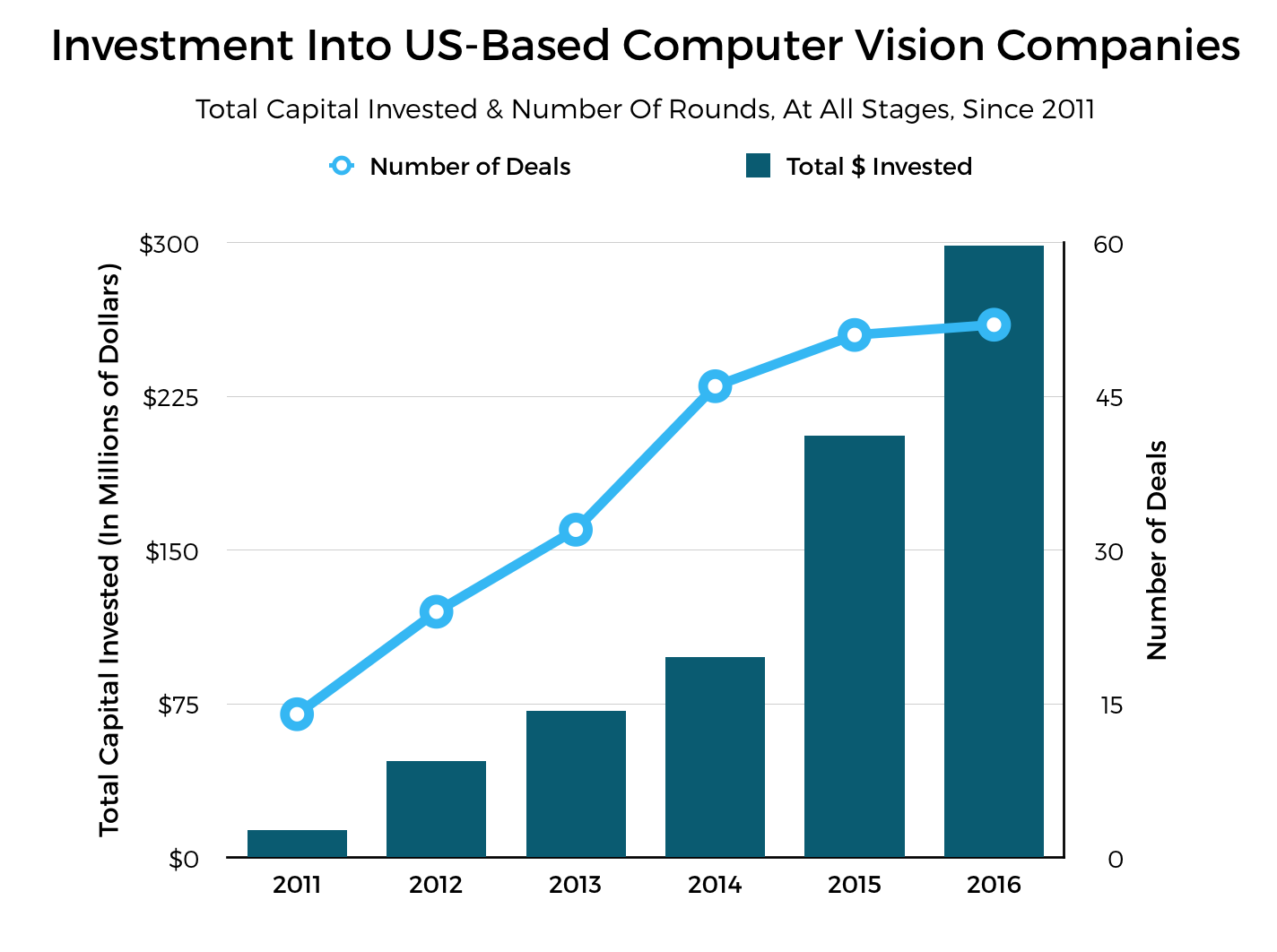
You can safely say that deep learning put computer vision on the map in the industry. Without it, chances are we would all still be stuck with it in academia (not that there’s anything wrong with academia, of course).
Large Datasets
To allow a machine to learn the underlying patterns of classes of objects it needs A LOT of data. That is, it needs large datasets. More and more of these have been emerging and have been instrumental in the success of deep learning and therefore computer vision.
Before around 2012, a dataset was considered relatively large if it contained 100+ images or videos. Now, datasets exist with numbers ranging in the millions.
Here are some of the most known image classification databases currently being used to test and train the latest state-of-the-art object classification/recognition models. They have all been meticulously hand annotated by the open source community.
- ImageNet – 15 million images, 22,000 object categories. It’s HUGE! (I hope to write more about this dataset in the near future, so stay tuned for that).
- Open Images – 9 million images, 5,000 object categories.
- Microsoft Common Objects in Context (COCO) – 330K images, 80 object categories.
- PASCAL VOC Dataset – a few versions exist, 20 object categories.
- CALTECH-101 – 9,000 images with 101 object categories.
I need to also mention Kaggle, the University of California, Irvine Machine Learning Repository. Kaggle hosts 351 image datasets ranging from flowers, wines, forest fires, etc. It is also the home of the famous Facial Expression Recognition Challenge (FER). The aim of this competition is to correctly detect the emotion of people from seven different categories from nearly 35,000 images of faces.
All these datasets and many more have raised computer vision to its current position in the industry. Certainly, deep learning would not be where it is now without them.
More Applications
Faster machines, larger memories, and other advances in technology have increased the number of useful things machines have been able to do for us in our lives. We now have autonomous cars (well, we’re close to having them), drones, factory robots, cleaning robots – the list goes on. With an increase in such vehicles, devices, tools, appliances, etc. has come an increase in the need for computer vision.
Let’s take a look at some examples of recent new ways computer vision is being used today.
Walmart, for example, a few months ago released shelf-scanning robots into 50 of its warehouses. The purpose of these robots is to detect out-of-stock and missing items and other things such as incorrect labelling. Here’s a picture of one of these robots at work:

A British online supermarket is using computer vision to determine the best ways to grasp goods for its packaging robots. This video shows their robot in action:
Agriculture as well is capitalising on the growth of computer vision. iUNU, for example, is developing a network of cameras on rails to assist greenhouse owners to keep track of how their plants are growing.
The famous Roomba autonomous vacuum cleaner got an upgrade a few years ago with a new computer vision system to more smartly manoeuvre around your home.
And our phones? Plenty of computer vision being used in them! Ever noticed your phone camera tracking and focusing on your face when you’re trying to take a picture? That’s computer vision. And how about the face recognition services to unlock your phones? Well, Samsung’s version of it can be classified as computer vision (I write about it in this post).
There’s no need to mention autonomous cars here. We are constantly hearing about them on the news. It’s only a matter of time before we’ll be jumping into one.
Computer vision is definitely here to stay. In fact, it’s only going to get bigger with time.
Summary
In this post I looked at the four main reasons behind the recent growth of computer vision: 1) the advancements in hardware such as faster CPUs and availability of GPUs; 2) the emergence of deep learning, which has changed our way of performing tasks such as image classification; 3) the advent of large datasets that have allowed us to more meticulously study the underlying patterns in images; and 4) the increase in computer vision applications.
All these factors (not always mutually exclusive) have contributed to the unprecedented position of computer vision in the industry.
As I mentioned in my previous post, it’s been an absolute pleasure to have witnessed this growth and to have seen these factors in action. I truly look forward to what the future holds for computer vision.
To be informed when new content like this is posted, subscribe to the mailing list:



One Reply to “The Reasons Behind the Recent Growth of Computer Vision”