
Oh, I love stumbling upon fascinating publications from the academic world! This post will present to you yet another one of those little gems that has recently fallen into my lap. It’s on the topic of image completion and comes from a paper published in SIGGRAPH 2017 entitled “Globally and Locally Consistent Image Completion” (project page can be found here).
(Note: SIGGRAPH, which stands for “Special Interest Group on Computer GRAPHics and Interactive Techniques”, is a world renowned annual conference held for computer graphics researchers. But you do sometimes get papers from the world of computer vision being published there as is the case with the one I’m presenting here.)
This post will be divided into the following sections:
- What is image completion and some of its prior weaknesses
- An outline of the solution proposed by the above mentioned SIGGRAPH publication
- A presentation of results
If anything, please scroll down to the results section and take a look at the video published by the authors of the paper. There’s some amazing stuff to be seen there!
1. What is image completion?
Image completion is a technique for filling-in target regions with alternative content. A major use for image completion is in the task of object removal where an object from a photo is erased and the remaining hole is automatically substituted with content that hopefully maintains the contextual integrity of the image.
Image completion has been around for a while. Perhaps the most famous algorithm in this area is called PatchMatch which is used by Photoshop in its Content Aware Fill feature. Take a look at this example image generated by PatchMatch after the flowers in the bottom right corner were removed from the left image:

Not bad, hey? But the problem with existing solutions such as PatchMatch is that images can only be completed with textures that solely come from the input image. That is, calculations for what should be plugged into the hole are done using information obtained just from the input image. So, for images like the flower picture above, PatchMatch works great because it can work out that green leaves is the dominant texture and make do with that.
But what about more complex images… and faces as well? You can’t work out what should go into a gap in an image of a face just from its input image. This is an image completion example done on a face by PatchMatch:
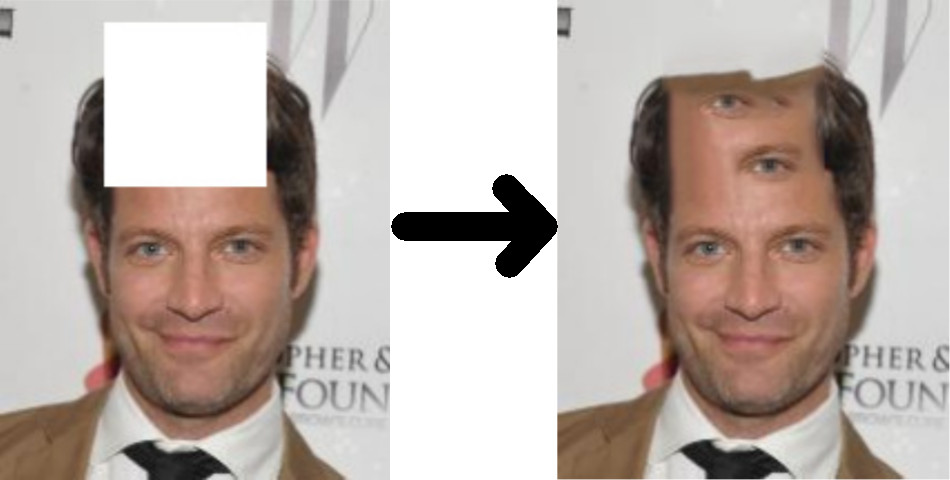
Yeah, not so good now, is it? You can see how trying to work out what should go into a gap from other areas of the input image is not going to work for a lot of cases like this.
2. Proposed solution
This is where the paper “Globally and Locally Consistent Image Completion” comes in. The idea behind it, in a nutshell, is to use a massive database of images of natural scenes to train a single deep learning network for image completion. The Places2 dataset is used for this, which contains over 8 million images of diverse natural scenes – a massive database from which the network basically learns the consistency inherent in natural scenes. This means that information to fill in missing gaps in images is obtained from these 8 million images rather than just one single image!
Once this deep neural network is trained for image completion, a GAN (Generative Adversarial Network) approach is utilised to further improve this network.
GAN is an unsupervised neural network training technique where one or more neural networks are used to mutually improve each other in the training phase. One neural network tries to fool another and all neural networks are updated according to results obtained from this step. You can leave these neural networks running for a long time and watch them improving each other.
The GAN technique is very common in computer vision nowadays in scenarios where one needs to artificially produce images that appear realistic.
Two additional networks are used in order to improve the image completion network: a global and a local context discriminator network. The former discriminator looks at the entire image to assess if it is coherent as a whole. The latter looks only at the small area centered at the completed region to ensure local consistency of the generated patch. In other words, you get two additional networks assisting in the training: one for global consistency and one local consistency.
These two auxiliary networks return a result stating whether the generated image is realistic-looking or artificial. The image completion network then tries to generate completed images to fool the auxiliary networks into thinking that their real.
In total, it took 2 months for the entire training stage to complete on a machine with four high-end GPUs. Crazy!
The following image shows the solution’s training architecture:
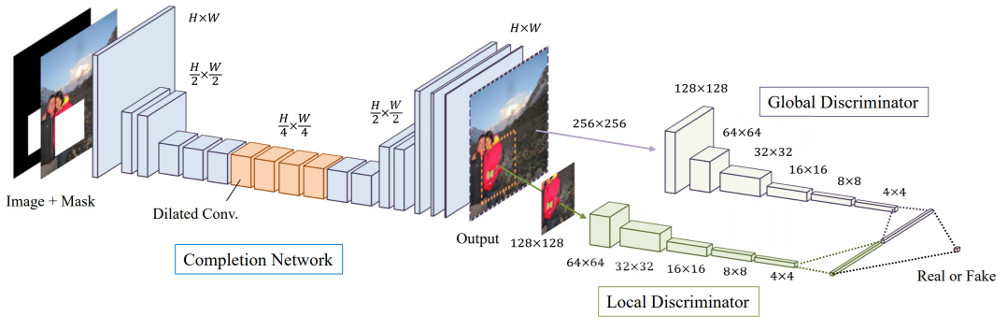
Typically, to complete an image of 1024 x 1024 resolution that has one gap takes about 8 seconds on a machine with a single CPU or 0.5 seconds on one with a decent GPU. That’s not bad at all considering how good the generated results are – see the next section for this.
3. Results
The first thing you need to do is view the results video released by the authors of the publication. Visit their project page for this and scroll down a little. I can provide a shorter version of this video from YouTube here:
As for concrete examples, let’s take a look at some faces first. One of these faces is the same from the PatchMatch example above.
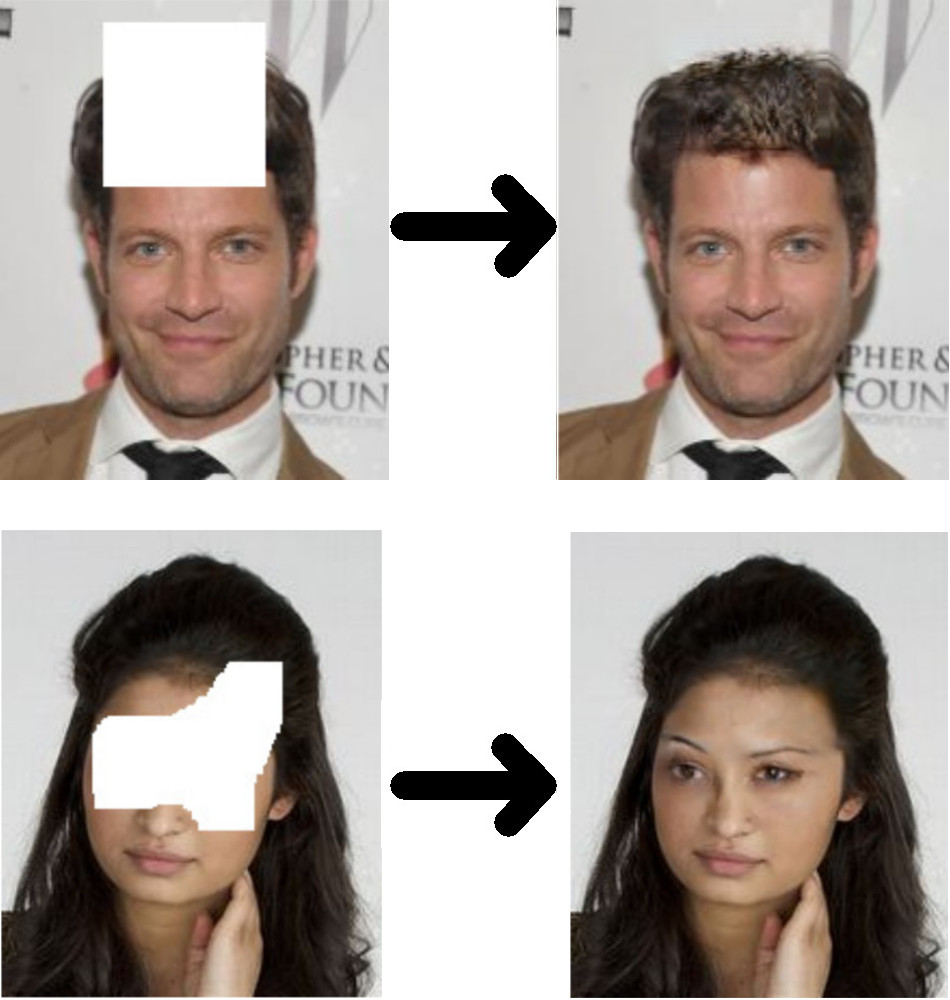
How’s impressive is this?
My favourite examples are of object removal. Check this out:

Look how the consistency of the image is maintained with the new patch in the image. It’s quite incredible!
My all-time favourite example is this one:

Absolutely amazing. More results can be viewed in supplementary material released by the authors of the paper. It’s well-worth a look!
Summary
In this post I presented a paper on image completion from SIGGRAPH 2017 entitled “Globally and Locally Consistent Image Completion”. I first introduced the topic of image completion, which is a technique for filling-in target regions with alternative content, and described some weaknesses of previous solutions – mainly that calculations for what should be generated for a target region are done using information obtained just from the input image. I then presented the more technical aspect of the proposed solution as presented in the paper. I showed that the image completion deep learning network learnt about global and local consistency of natural scenes from a database of over 8 million images. Then, a GAN approach was used to further train this network. In the final section of the post I showed some examples of image completion as generated by the presented solution.
To be informed when new content like this is posted, subscribe to the mailing list (or subscribe to my YouTube channel!):


One Reply to “Image Completion from SIGGRAPH 2017”