(Update: this post is part 2 of a 3 part series on CV and fashion. Part 1 can be found here, part 3 can be found here.)
In my last post I introduced the fashion industry and I gave an example of what Microsoft recently did in this field with computer vision. In today’s post, I would like to show you what the academic world has recently been doing in this respect.
It’s interesting to follow the academic world because every so often what you see happening there ends up being brought into our everyday lives. Artificial intelligence, with deep learning at the forefront, is a prime example of this. Hence why I’m always keen to keep up-to-date with the goings-on of computer vision in academia.
A good way to keep abreast of computer vision in the academic world is to follow two of the top conferences in the field: the International Conference on Computer Vision (ICCV) and the Conference on Computer Vision and Pattern Recognition (CVPR). These annual conferences are huge. This is where the best of the best come together; where the titans of computer vision pit their wits against each other. Believe me, publishing in either one of these conferences is a lifetime achievement. I have 10 publications in total there (that’s a lie… I have none :P).
Interestingly, the academic world has been eyeing the fashion industry for the last 5 years it seems. An analysis was performed by Fashwell recently that counted the number of fashion-related papers at these two conferences. There appears to be a steady increase in these since 2013, as the graph below depicts:

Notice, the huge spike at the end? The reason for it is that ICCV last year held an entire workshop specifically devoted to fashion!
(Note: a workshop is a, let’s say, less-formal format of a conference usually held as a side event to a major conference. Despite this, publishing at an ICCV or CVPR workshop is still a major achievement.)
As a result, there is plenty of material for me to present to you on the topic of computer vision in the fashion industry. Let’s get cracking!
ICCV 2017
In this post I will present two closely-related papers to you from the 2017 ICCV conference (in my next post I’ll present a few from the workshop):
- “Be Your Own Prada: Fashion Synthesis With Structural Coherence” (Zhu, et al., ICCV, 2017, pp. 1680-1688) [source code]
- “A Generative Model of People in Clothing” (Lassner, et al., ICCV, 2017, pp. 853-862) [source code]
Just like with all my posts, I will give to you an overview of these publications. Most papers published at this level require a (very) strong academic background to fully grasp, so I don’t want to go into that much detail here.
But I have provided links to the source code of these papers, so please feel free to download, install and play around with these beauties at home.
1. Be Your Own Prada
This is a paper that presents an algorithm that can generate new clothing on an existing photo of a person without changing the person’s shape or pose. The desired new outfit is provided as a sentence description, e.g.: “a white blouse with long sleeves but without a collar and blue jeans”.
This is an interesting idea! You can provide the algorithm with a photo of yourself and then virtually try on a seemingly endless combination of styles of shirts, dresses, etc.
“Do I look good in blue and red? I dunno, but let’s find out!”
Neat, hey?
The algorithm has a two-step process:
- Image segmentation. This step semantically breaks the image up into human body parts such as face, arms, legs, hips, torso, etc. The result basically captures the shape of the person’s body
and parts, but not their appearance, as shown in the example image below. Also, along with image segmentation, other attributes are extracted such as skin colour, long/short hair, and gender to provide constraints and boundaries for how far the image rendering step can go (you don’t want to change the person’s skin or hair colour, for example). The segmentation step is performed using a trained generative adversarial network (GAN – see this post for a description of these).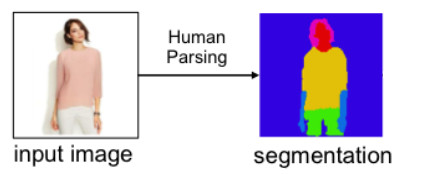
(image adapted from original publication) - Image rendering. This is the part that places new outfits onto the person using the results (segmentation and constraints/boundaries) from the first step as a guide. GANs are used here again. Example clothing articles were taken from 80,000 annotated images selected from the DeepFashion dataset.
Let’s take a look at some results (taken from the original publication). Remember, all that is provided is one picture of a person and then a description of how that person’s outfit should look like:

Pretty cool! You could really see yourself using this, couldn’t you? We might be using something like this on our phones soon, I would say. Take a look at the authors’ page for this paper for more example result images. Some amazing stuff there.
2. A Generative Model of People in Clothing
This paper is still a work in progress, meaning that more research is needed before anything from it gets rolled out for everyday use. The intended goal of the algorithm is similar to the one presented above but instead of being able to generate images of the same person wearing a different outfit, this algorithm can generate random images of different people wearing different attires. Usually, generating such images is achieved after following a complex 3D graphics rendering pipeline.
It is a very complex algorithm but, in a nutshell, it first creates a dataset containing human pose, shape, and face information along with clothing articles. This information is then used to learn the relationships between body parts and respective clothes and how these clothes fit nicely to its appropriate body part, depending on the person’s pose and shape.
The dataset is created using the SMPLify 3D pose and shape estimation algorithm on the Chictopia10K fashion dataset (that was collected from the Chictopia fashion website) as well as dlib‘s implementation of the fast facial shape matcher to enhance each image with facial information.
Let’s take a look at some results.
The image below shows a randomly generated person wearing different coloured clothes (provided manually). Notice that, for example, with the skirts, the model learnt to put different wrinkles on the skirt depending on its colour. Interesting, isn’t it? The face on the person seems out of place – one reason why the algorithm is still a work in progress.

The authors of the paper also attempted to create a random fashion magazine photo dataset from their algorithm. The idea behind this was to show that fashion magazines could perhaps one day generate photos automatically without going through the costly process of setting up photo sessions with real people. Once again, the results leave a lot to be desired but it’s interesting to see where research is heading.

Summary
This post extended my last post on computer vision in the fashion industry. I first examined how fashion is increasingly being looked at in computer vision academic circles. I then presented two papers from ICCV 2017. The first paper describes an algorithm to generate a new attire on an existing photo of a person without changing the person’s shape or pose. The desired new outfit is provided as a sentence description. The second paper shows a work-in-progress algorithm to randomly generate people wearing different clothing attires.
It’s interesting to follow the academic world because every so often what you see happening there ends up being brought into our everyday lives.
(Update: this post is part 2 of a 3 part series on CV and fashion. Part 1 can be found here, part 3 can be found here.)
—
To be informed when new content like this is posted, subscribe to the mailing list (or subscribe to my YouTube channel!):


2 Replies to “Computer Vision in the Fashion Industry – Part 2”