
In previous posts of mine I have discussed how image datasets have become crucial in the deep learning (DL) boom of computer vision of the past few years. In deep learning, neural networks are told to (more or less) autonomously discover the underlying patterns in classes of images (e.g. that bicycles are composed of two wheels, a handlebar, and a seat). Since images are visual representations of our reality, they contain the inherent complex intricacies of our world. Hence, to train good DL models that are capable of extracting the underlying patterns in classes of images, deep learning needs lots of data, i.e. big data. And it’s crucial that this big data that feeds the deep learning machine be of top quality.
In lieu of Google’s recent announcement of an update to its image dataset as well as its new challenge, in this post I would like to present to you the top 3 image datasets that are currently being used by the computer vision community as well as their associated challenges:
- ImageNet and ILSVRC
- Open Images and the Open Images Challenge
- COCO Dataset and the four COCO challenges of 2018
I wish to talk about the challenges associated with these datasets because challenges are a great way for researchers to compete against each other and in the process to push the boundary of computer vision further each year!
ImageNet
 This is the most famous image dataset by a country mile. But confusion often accompanies what ImageNet actually is because the name is frequently used to describe two things: the ImageNet project itself and its visual recognition challenge.
This is the most famous image dataset by a country mile. But confusion often accompanies what ImageNet actually is because the name is frequently used to describe two things: the ImageNet project itself and its visual recognition challenge.
The former is a project whose aim is to label and categorise images according to the WordNet hierarchy. WordNet is an open-source database for words that are organised hierarchically into synonyms. For example words like “dog” and “cat” can be found in the following knowledge structure:
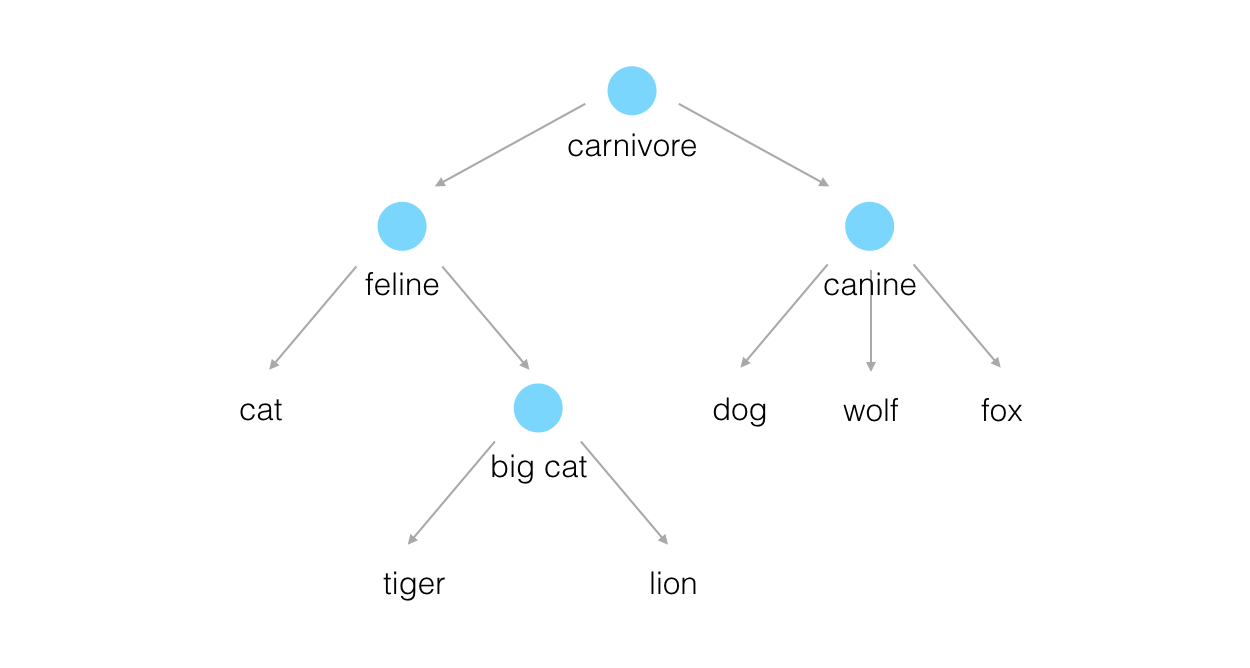
Each node in the hierarchy is called a “synonym set” or “synset”. This is a great way to categorise words because whatever noun you may have, you can easily extract its context (e.g. that a dog is a carnivore) – something very useful for artificial intelligence.
The idea with the ImageNet project, then, is to have 1000+ images for each and every synset in order to also have a visual hierarchy to accompany WordNet. Currently there are over 14 million images in ImageNet for nearly 22,000 synsets (WordNet has ~100,000 synsets). Over 1 million images also have hand-annotated bounding boxes around the dominant object in the image.

You can explore the ImageNet and WordNet dataset interactively here. I highly recommend you do this!
Note: by default only URLs to images in ImageNet are provided because ImageNet does not own the copyright to them. However, a download link can be obtained to the entire dataset if certain terms and conditions are accepted (e.g. that the images will be used for non-commercial research).
Having said this, when the term “ImageNet” is used in CV literature, it usually refers to the ImageNet Large Scale Visual Recognition Challenge (ILSVRC) which is an annual competition for object detection and image classification. This competition is very famous. In fact, the DL revolution of the 2010s is widely attributed to have originated from this challenge after a deep convolutional neural network blitzed the competition in 2012.
The motivation behind ILSVRC, as the website says, is:
… to allow researchers to compare progress in detection across a wider variety of objects — taking advantage of the quite expensive labeling effort. Another motivation is to measure the progress of computer vision for large scale image indexing for retrieval and annotation.
The ILSVRC competition has its own image dataset that is actually a subset of the ImageNet dataset. This meticulously hand-annotated dataset has 1,000 object categories (the full list of these synsets can be found here) spread over ~1.2 million images. Half of these images also have bounding boxes around the class category object.
The ILSCVRC dataset is most frequently used to train object classification neural network frameworks such as VGG16, InceptionV3, ResNet, etc., that are publicly available for use. If you ever download one of these pre-trained frameworks (e.g. Inception V3) and it says that it can detect 1000 different classes of objects, then it most certainly was trained on this dataset.
Google’s Open Images
Google is a new player in the field of datasets but you know that when Google does something it will do it with a bang. And it has not disappointed here either.
Open Images is a new dataset first released in 2016 that contains ~9 million images – which is fewer than ImageNet. What makes it stand out is that these images are mostly of complex scenes that span thousands of classes of objects. Moreover, ~2 million of these images are hand-annotated with bounding boxes making Open Images by far the largest existing dataset with object location annotations. In this subset of images, there are ~15.4 million bounding boxes of 600 classes of object. These objects are also part of a hierarchy (see here for a nice image of this hierarchy) but one that is nowhere near as complex as WordNet.

As of a few months’ ago, there is also a challenge associated with Open Images called the “Open Images Challenge“. It is an object detection challenge and, what’s more interesting, there is also a visual relationship detection challenge (e.g. “woman playing a guitar” rather than just “guitar” and “woman”). The inaugural challenge will be held at this year’s European Conference on Computer Vision. It looks like this will be a super interesting event considering the complexity of the images in the dataset and, as a result, I foresee this challenge to be the de facto object detection challenge in the near future. I am certainly looking forward to seeing the results of the challenge to be posted around the time of the conference (September 2018).
Microsoft’s COCO Dataset
Microsoft is in this game also with their Common Objects in Context (COCO) dataset. Containing ~200K images, it’s relatively small but what makes it stand out are its challenges that come associated with the additional features it provides for each image, for example:
- object segmentation information rather than just bounding boxes of objects (see image below)
- five textual captions per image such as “the a380 air bus ascends into the clouds” and “a plane flying through a cloudy blue sky”.
The first of these points is worth providing an example image of:

Notice how each object is segmented rather than outlined by a bounding box as is the case with ImageNet and Open Images examples? This object segmentation feature of the dataset makes for very interesting challenges because segmenting an object like this is many times more difficult than just drawing a rectangular box around it.
COCO challenges are also held annually. But each year’s challenge is slightly different. This year the challenge has four tracks:
- Object segmentation (as in the example image above)
- Panoptic segmentation task, which requires object and background scene segmentation, i.e. a task to segment the entire image rather than just the dominant objects in an image:

- Keypoint detection task, which involves simultaneously detecting people and localising their keypoints:

- DensePose task, which involves simultaneously detecting people and localising their dense keypoints (i.e. mapping all human pixels to a 3D surface of the human body):

Very interesting, isn’t it? There is always something engaging taking place in the world of computer vision!
To be informed when new content like this is posted, subscribe to the mailing list:

5 Replies to “The Top Image Datasets and Their Challenges”