(image source)
(Update: this post is the first of a 3-part series. Part 2 can be found here, part 3 can be found here)
Computer vision has a plethora of applications in the industry: cashier-less stores, autonomous vehicles (including those loitering on Mars), security (e.g. face recognition) – the list goes on endlessly. I’ve already written about the incredible growth of this field in the industry and, in a separate post, the reasons behind it.
In today’s post I would like to discuss computer vision in a field that I haven’t touched upon yet: the fashion industry. In fact, I would like to devote my next few posts to this topic because of how ingeniously computer vision is being utilised in it.
In this post I will introduce the fashion industry and then present something that Microsoft recently did in the field with computer vision.
In my next few posts (part 2 here; part 3 here) I would like to present what the academic world (read: cutting-edge research) is doing in this respect. You will see quite amazing things there, so stay tuned for that!
The Fashion Industry
The fashion industry is huge. And that’s probably an understatement. At present it is estimated to be worth US$2.4 trillion. How big is that? If the fashion industry were a country, it would be ranked as the 7th largest economy in the world – above my beloved Australia and other countries like Russia and Spain. Utterly huge.
Moreover, it is reported to be growing at a steady rate of 5.5% each year.
On the e-commerce market, the clothing and fashion sectors dominate. In the EU, for example, the majority of the 530 billion euro e-commerce market is made up of this industry. Moreover, The Economic Times predicts that the online fashion market will grow three-fold in the next few years. The industry appears to be in agreement with this forecast considering some of the major takeovers being currently discussed. The largest one on the table at the moment is of Flipkart, India’s biggest online store that attributes 50% of its transactions to fashion. Walmart is expected to win the bidding war by purchasing 73% of the company that it has valued at US$22 billion. Google is expected to invest a “measly” US$3 billion also. Ridiculously large amounts of money!
So, if the industry is so huge, especially online, then it only makes sense to bring artificial intelligence into play. And since fashion is a visual thing, this is a perfect application for computer vision!
(I’ve always said it: now is a great time to get into computer vision)
Microsoft and the Fashion Industry
3 weeks ago, Microsoft published on their Developer Blog an interesting article detailing how they used deep learning to build an e-commerce catalogue visual search system for “a successful international online fashion retailer” (which one it was has not been disclosed). I would like to present a summary of this article here because I think it is a perfect introduction to what computer vision can do in the fashion industry. (In my next post you will see how what Microsoft did is just a drop in the ocean compared to what researches are currently able to do).
The motivation behind this search system was to save this retailer’s time in finding whether each new arriving item matches a merchandise item already in stock. Currently, employees have to manually look through catalogues and perform search and retrieval tasks themselves. For a large retailer, sifting through a sizable catalogue can be a time consuming and tedious process.
So, the idea was to be able to take a photo from a mobile phone of a piece of clothing or footwear and search for it in a database for matches.
You may know that Google already has image search functionalities. Microsoft realised, however, that for their application in fashion to work, it was necessary to construct their own algorithm that would include some initial pre-processing of images. The reason for this is that the images in the database had a clean background whereas if you take a photo on your phone in a warehouse setting, you will capture a noisy background. The images below (taken from the original blog post) show this well. The first column shows a query image (taken by a mobile phone), the second column the matching image in the database.


Microsoft, hence, worked on a background subtraction algorithm that would remove the background of an image and only leave the foreground (i.e. salient fashion item) behind.
Background subtraction is a well-known technique in the computer vision field and it is by all means still an open area of research. OpenCV in fact has a few very interesting implementations available of background subtraction. See this OpenCV tutorial for more information on these.
GrabCut
Microsoft decided not to use these but instead to try out other methods for this task. It first tried GrabCut, a very popular background segmentation algorithm first introduced in 2004. In fact, this algorithm was developed by Microsoft researchers to which Microsoft still owns the patent rights (hence why you won’t find it in the main repository of OpenCV any more).
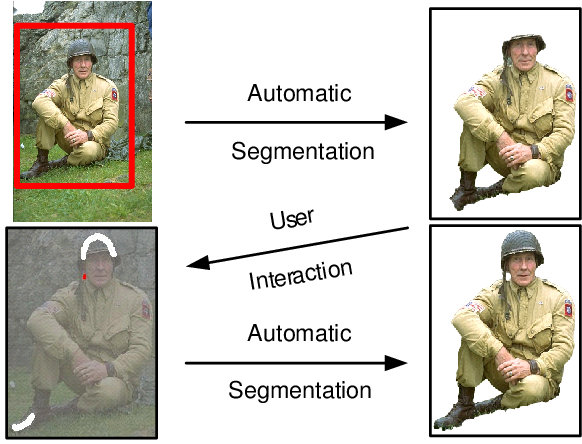
I won’t go into too much detail on how GrabCut works but basically, for each image, you first need to manually provide a bounding box of the salient object in the foreground. After that, GrabCut builds a model (i.e. a mathematical description) of the background (area outside of the bounding box) and foreground (area inside the bounding box) and using these models iteratively trims inside the rectangle until it deduces where the foreground object lies. This process can be repeated by then manually indicating where the algorithm went wrong inside the bounding box.
The image below (from the original publication of 2004) illustrates this process. Note that the red rectangle was manually provided as were also the white and red strokes in the bottom left image.
The images below show some examples provided by Microsoft from their application. The first column shows raw images from a mobile phone taken inside a warehouse, the second column shows initial results using GrabCut, and the third column shows images using GrabCut after additional human interaction. These results are pretty good.

Tiramisu
But Microsoft wasn’t happy with GrabCut for the important reason of it requiring human interaction. It wanted a solution that would work simply by only providing a photo of a product. So, it decided to move to a deep learning solution: Tiramisu (Yum, I love that cake…)
Tiramisu is a type of DenseNet, which in turn is a specific type of Convolutional Neural Network (CNN). Once again, I’m not going to go into detail on how this network works. For more information see this publication that introduced DenseNets and this paper that introduced Tiramisu. But basically DenseNets connect each layer to every other layer whereas CNN layers have connections with only their nearest layers.
DenseNets work (suprisingly?) well on relatively small datasets. For specific tasks using deep neural networks, you usually need a few thousand example images for each class you are trying to classify for. DenseNets can get remarkable results with around 600 images (which is still a lot but it’s at least a bit more manageable).
So, Microsoft trained a Tiramisu model from scratch with two classes: foreground and background. Only 249 images were provided for each class! The foreground and background training images were segmented using GrabCut with human interaction. The model achieved an accuracy rate of 93.7% at the training stage. The example image below shows an original image, the corresponding labelled training image (white is foreground and black is background), and the predicted Tiramisu result. Pretty good!

How did it fare in the real world? Apparently quite well. Here are some example images. The top row shows the automatically segmented image (i.e. with the background subtracted out) and the bottom row shows the original input images. Very neat 🙂

The segmented images (e.g. top row in the above image) were then used to query a database. How this querying took place and what algorithm was used to detect potential matches is, however, not described in the blog post.
Microsoft has released all their code from this project so feel free to take a look yourselves.
Summary
In this post I introduced the topic of computer vision in the fashion industry. I described how the fashion industry is a huge business currently worth approximately US$2.4 trillion and how it is dominating on the online market. Since fashion is a visual trade, this is a perfect application for computer vision.
In the second part of this post I looked at what Microsoft did recently to develop a catalogue visual search system. They performed background subtraction on photos of fashion items using a DenseNet solution and these segmented images were used to query an already-existing catalogue.
Stay tuned for my next post which will look at what academia has been doing with respect to computer vision and the fashion industry.
(Update: this post is the first of a 3-part series. Part 2 can be found here, part 3 can be found here)
—
To be informed when new content like this is posted, subscribe to the mailing list:

Hi man. Could you please update the images on the post? Thanks. Nice blog.
Hello! Hmm, I don’t know what happened here. I’ll try to fix this post up soon. Hopefully I still have access to the old images. Zig