How many times have we seen in a film somebody request security footage to be enhanced? Lots. We know it’s rubbish but in this post I present a possible scenario where this might actually be feasible.

Posts discussing image enhancing technology
How many times have we seen in a film somebody request security footage to be enhanced? Lots. We know it’s rubbish but in this post I present a possible scenario where this might actually be feasible.

In today’s post, I wish to talk about new technology that has recently emerged from Google that’s related to the image enhancing topic discussed in a previous post of mine.
Michael F. Cohen, the Director of Facebook’s Computational Photography Research team, has received the 2019 Coons Award for Outstanding Creative Contributions to Computer Graphics. Here is one of his contributions to photography.

A few days ago Nokia unveiled its new smartphone: the Nokia 9 PureView. It looks kind of weird (or maybe funky?) with its 5 cameras at its rear (see image above). But what’s interesting is how Nokia uses these 5 cameras to give you better quality photos with a technique called High Dynamic Range (HDR) imaging. […]

I got another great academic publication to present to you – and this publication also comes with an online interactive website for you to use to your heart’s content. The paper is from the field of image colourisation. Image colourisation (or ‘colorization’ for our US readers :P) is the act of taking a black and white […]

Oh, I love stumbling upon fascinating publications from the academic world! This post will present to you yet another one of those little gems that has recently fallen into my lap. It’s on the topic of image completion and comes from a paper published in SIGGRAPH 2017 entitled “Globally and Locally Consistent Image Completion” (project page […]
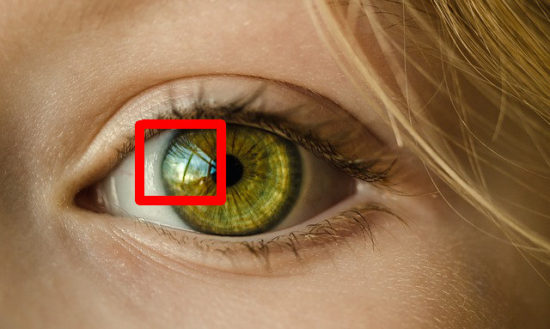
Ever thought about whether you could zoom in on someone’s eye in a photo and analyse the reflection on it? Read on to find out what research has done in this respect! A previous post of mine discussed the idea of enhancing regions in an image for better clarity much like we often see in Hollywood […]
I was rewatching “Bourne Identity” the other day. Love that flick! Heck, the scene at the end is one of my favourites. Jason Bourne grabs a dead guy, jumps off the top floor landing, and while falling shoots a guy square in the middle of the forehead. He then breaks his fall on the dead […]