I present here Google’s AI model that generates video games from a single input image (whether hand-drawn, generated or a photo)

Posts presenting new academic papers
I present here Google’s AI model that generates video games from a single input image (whether hand-drawn, generated or a photo)

Last month Google’s AI research group published an academic paper in which they set out to define artificial general intelligence. I summarise this paper and provide my own commentary.

An academic study has found that ChatGPT is left-leaning in terms of its political standpoints, despite its official stance of neutrality. I discuss here the implications of these findings.

In today’s post, I wish to talk about new technology that has recently emerged from Google that’s related to the image enhancing topic discussed in a previous post of mine.
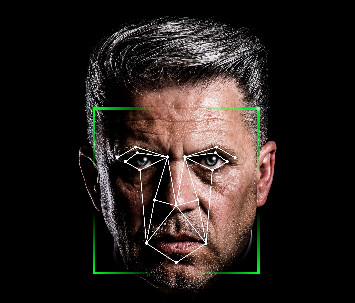
Here I describe a specific facial recognition algorithm – one that changed things forever: FaceNet by Google.

I present to you a paper from ICCV 2019 that proposes a fast and impressive method to de-identify videos in real-time. We all more privacy in our lives.
Michael F. Cohen, the Director of Facebook’s Computational Photography Research team, has received the 2019 Coons Award for Outstanding Creative Contributions to Computer Graphics. Here is one of his contributions to photography.

In this post show you some results of a paper that was published in the prestigious Nature journal. It’s on the topic of non-line-of-sight imaging or, in other words, it’s about trying to see around corners.

Heart rate estimation belongs in the field called “Vital Signal Estimation”. One famous attempt at this comes from a paper entitled “Eulerian Video Magnification for Revealing Subtle Changes in the World”

I got another great academic publication to present to you – and this publication also comes with an online interactive website for you to use to your heart’s content. The paper is from the field of image colourisation. Image colourisation (or ‘colorization’ for our US readers :P) is the act of taking a black and white […]